Continuando a serie do pipeline de dados, agora iremos fazer a preparação do ambiente em MySQL e realizar o processo de ingestão de dados com o Streamsets.
Nessa etapa iremos adicionar dois novos itens em nosso pipeline.
O primeiro é o docker-compose, que servirá de gerenciador permitindo a orquestração e algumas definições importantes, como a rede.
O segundo um script bash em linux, ele reproduzirá um sistema que tem como saída um arquivo em um diretório.
Basicamente iremos ao site https://brasil.io/dataset/covid19/caso/ baixar os dados de covid-19 com esse script shell.
Caso você não tenha acompanhado a postagem anterior, ela é importante e parte dessa serie. Você pode encontra-lá nesse link: postagem-1
Agora vamos lá! 🙂
Ambiente
Mais uma vez utilizarei o docker como ferramenta para realizar o setup do ambiente. Também vou utilizar docker-compose para realizar a iniciação do ambiente, assim, podemos garantir os IP’s que serão utilizados.
O script abaixo demonstra como criar um contêiner para rodar um banco de dados MySQL, vamos salvar esse script como mysql.dockerfile.
FROM mysql:5.7.32
ENV MYSQL_ROOT_PASSWORD=12345Primeiro, vamos “buildar” a imagem do MySQL, o comando abaixo faz isso:
$ docker build -f mysql.dockerfile . -t mysql-streamsetsDevemos criar também um volume para a persistência dos dados. Para isso podemos utilizar o código abaixo:
$ docker volume create mysql-dataAssim, temos nosso volume e as imagens construídas, vamos iniciar os contêineres com o docker-compose. 😀
O script abaixo faz a preparação do ambiente, subindo os dois contêineres e definindo um endereço fixo de rede.
version: "3.3"
services:
streamsets:
image: streamsets
networks:
net-data-pipeline:
ipv4_address: 172.16.0.11
ports:
- "18630:18630"
volumes:
- streamsets-data:/opt/streamsets
mysql-db:
image: mysql-streamsets
networks:
net-data-pipeline:
ipv4_address: 172.16.0.10
ports:
- "3306:3306"
volumes:
- mysql-data:/var/lib/mysql
volumes:
streamsets-data:
mysql-data:
networks:
net-data-pipeline:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.16.0.0/24Salvamos esse script como o nome de env-docker-compose.yaml, vamos iniciar o docker-compose com o comando abaixo:
$ docker-compose -f env-docker-compose.yaml upAgora é possível acessar o Streamsets através do seguinte endereço: http://172.16.0.11:18630/
Lembrando que o login e senha padrões são admin/admin 🙂
Script Shell
Com nosso ambiente rodando, vamos criar o script shell para baixar os dados de covid-19.
Primeiro precisamos acessar nosso contêiner onde está o Streamsets. Dentro do contêiner, iremos criar uma pasta onde iremos manter o shell script e também os dados baixados.
O script abaixo lista os contêineres rodando, podemos acessar o contêiner do Streamsets pelo ID.
$ docker container lsO script abaixo acessa o contêiner pelo ID
$ docker exec -it ID_DO_CONTAINER /bin/bashVamos criar agora o diretório onde deixaremos o nosso script.
$ mkdir /opt/streamsets/app-dataFeito isso, utilizaremos o vim, editor de texto do linux via terminal, para criarmos e editarmos nosso arquivo.
Se digitarmos o comando abaixo, iremos criar o arquivo no diretório.
$ vi /opt/streamsets/app-data/pega_dados_covid.shTeremos a tela abaixo:
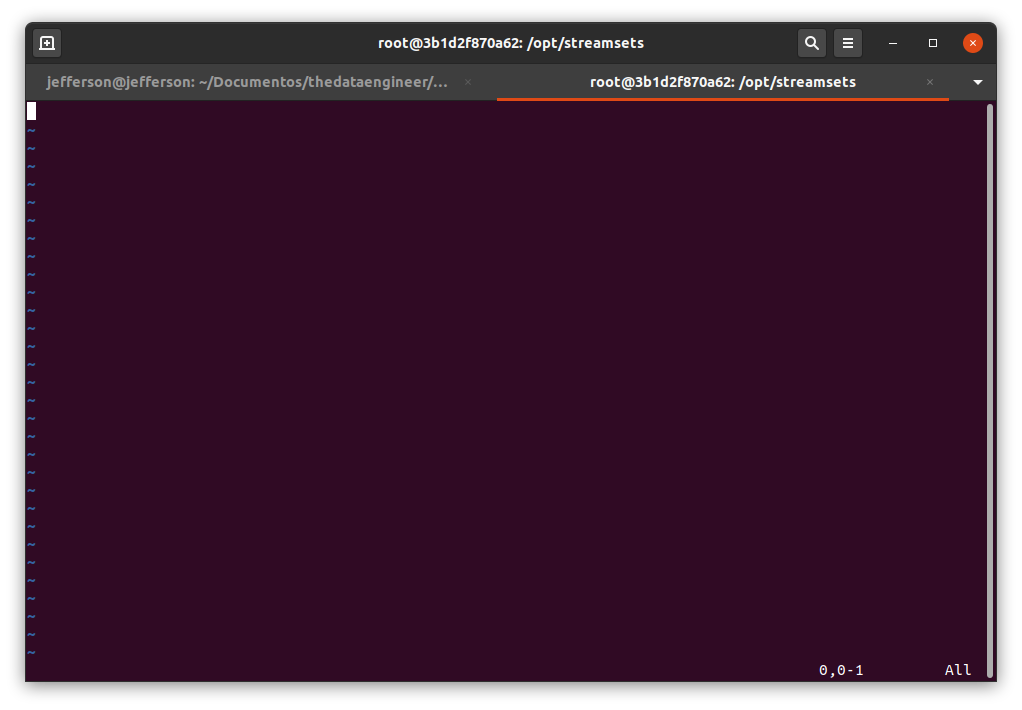
Para entrarmos no modo de inserção, devemos apertar a tecla “I”, a palavra “–INSERT–” deve aparecer no rodapé do terminal.
Agora, podemos colar o nosso código dentro do arquivo:
cd /opt/streamsets/app-data
wget https://data.brasil.io/dataset/covid19/caso_full.csv.gz
gunzip caso_full.csv.gzPara salvarmos os dados devemos apertar “ESC” depois “:” e então escrever “wq”.
Agora, podemos executar nosso script.
$ sh /opt/streamsets/app-data/pega_dados_covid.shEsse passo está terminado, poderíamos, se fosse o caso, agendar uma tarefa dentro do crontab do linux, e fazer esse script executar 1x ao dia, ou 2x ao dia.
MySQL
Antes de criarmos o pipeline dentro do Streamsets, vamos criar a tabela onde iremos carregar os dados.
Para isso, vou usar o script abaixo dentro do MySQL.
CREATE DATABASE IF NOT EXISTS COVID19;
CREATE TABLE IF NOT EXISTS T_CARGA_COVID
(
city varchar(50),
city_ibge_code int,
date date,
epidemiological_week int,
estimated_population int,
estimated_population_2019 int,
is_last BOOLEAN,
is_repeated BOOLEAN,
last_available_confirmed float,
last_available_confirmed_per_100k_inhabitants float,
last_available_date date,
last_available_death_rate float,
last_available_deaths float,
order_for_place int,
place_type varchar(10),
state varchar(5),
new_confirmed int,
new_deaths int
);Você pode usar qualquer interface para a comunicação, eu fiz através de um plugin do Visual Studio Code chamado “MySQL Client”.
Os dados para criar a conexão são:
Host: 172.16.0.10
Porta: 3306
Usuário: root
Senha: 12345
Streamsets
Acessamos o endereço do Streamsets: http://172.16.0.11:18630/
Os dados para login são:
Usuário: admin
Senha: admin
Bom, antes de iniciarmos o pipeline, vamos registrar o Streamsets. Isso será útil, pois, poderemos baixar outras opções dentro da plataforma.
Vamos no ícone de engrenagens e em “Activation”.
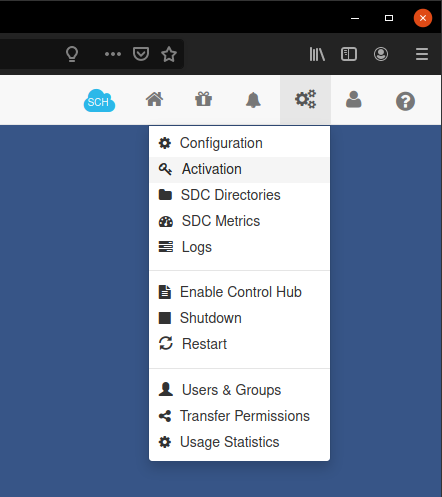
A janela abaixo será exibida, preenchemos os dados e eles enviam uma chave para ativação no e-mail.
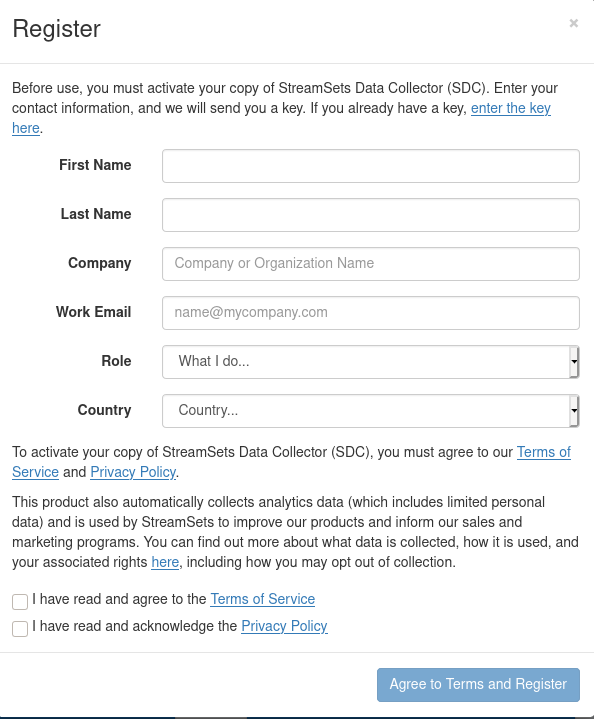
A tela abaixo aparecerá e então colocamos a chave recebida no e-mail e ativamos o produto.
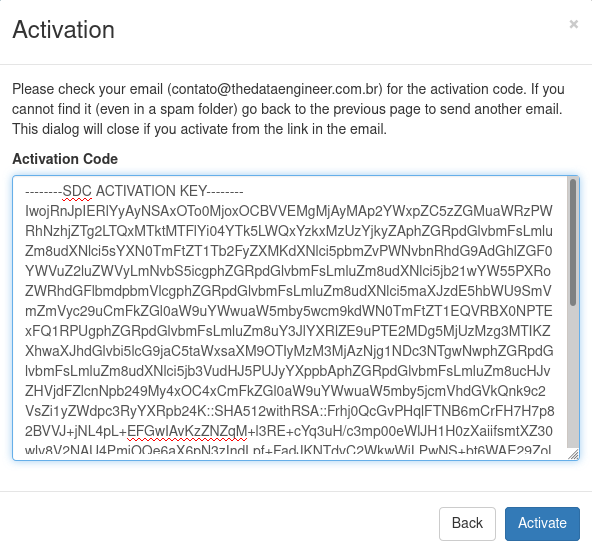
Prontinho! Agora vamos ao que interessa. 🙂
Pipeline
Primeiro vamos realizar a instalação de um pacote. Esse pacote é a conexão JDBC, que usaremos para conectar ao banco de dados.
Em “Package Manager”, o ícone do pacote, encontramos os pacotes já instalados. Dentro dele, podemos fazer a pesquisa por “JDBC”.
Abaixo o pacote será exibido:
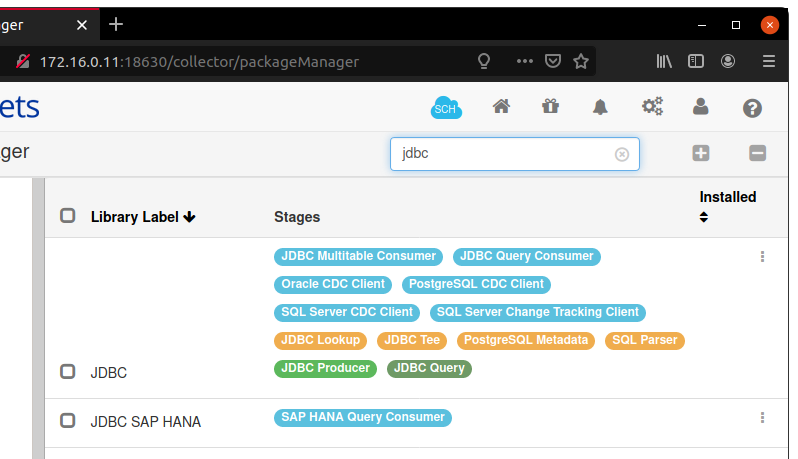
Nos três pontos, do lado direito, podemos encontrar a opção de instalação do pacote, clicamos e então iniciamos a instalação.
Depois da instalação, você pode reiniciar o serviço para que as alterações fiquem vigentes.
Ufa! Agora, vamos criar nosso pipeline! 🙂
Vamos em “CREATE NEW PIPELINE”, conforme a tela abaixo.
Agora, preenchemos o titulo, descrição e um label, caso queiramos.
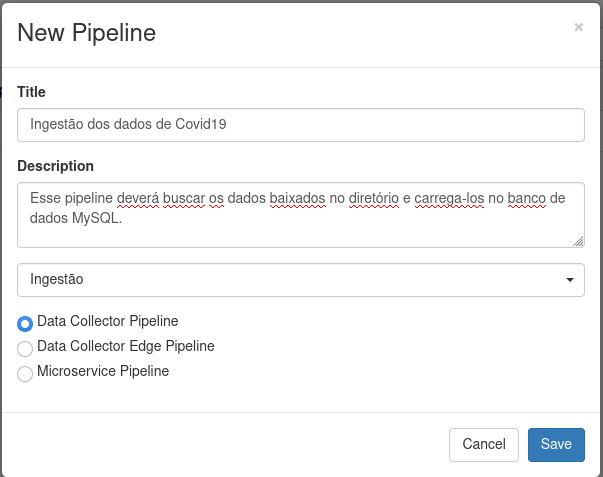
Concluindo esse passo, o Streamsets entra no pipeline, então vemos a seguinte janela:
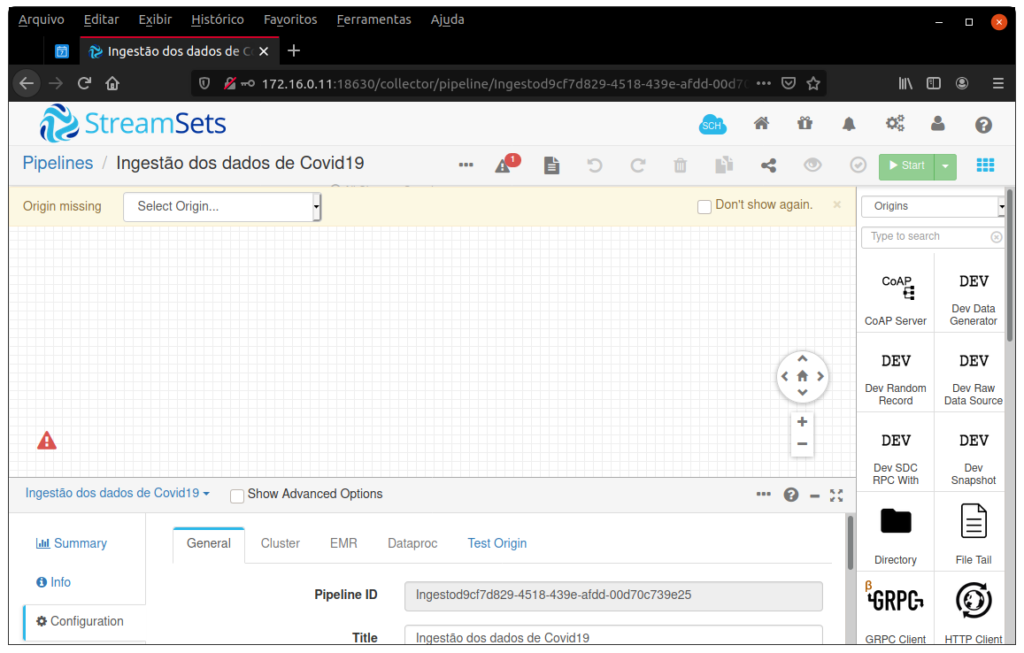
Como podem reparar na imagem, no canto direito temos diversos recursos para utilização, utilizaremos para ler o diretório o recurso “Directory”, pesquisando seu nome em “Type to search” .
O ícone do “Directory” será adicionado ao nosso pipeline, em suas configurações, na parte de baixo, devemos colocar os seguintes parâmetros:
General
Name: Dados Covid-19
Files
Files Directory: /opt/streamsets/app-data
File Name Pattern: caso_full.csv
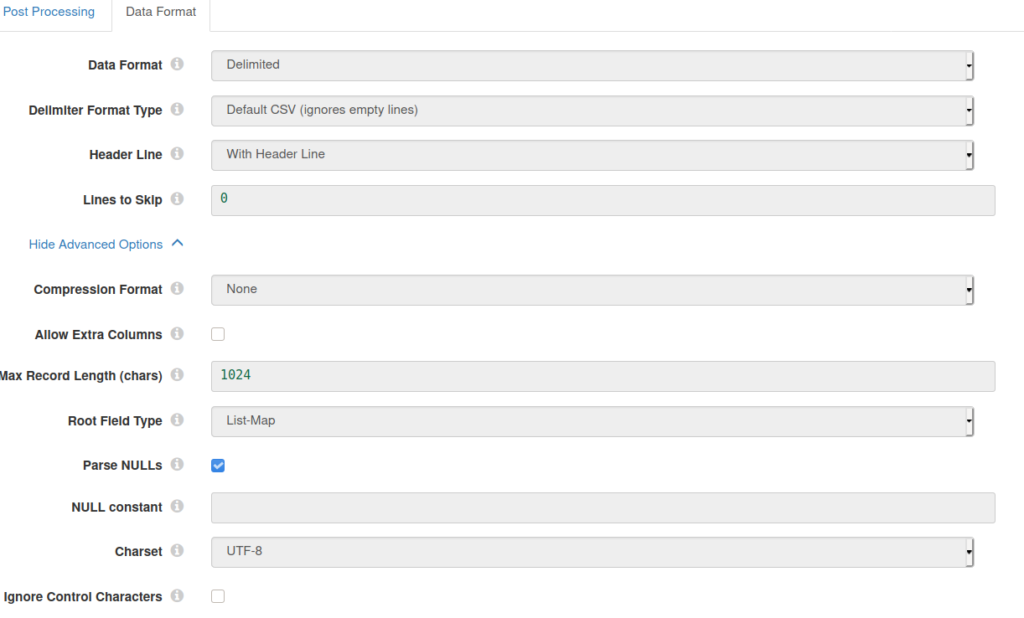
Data Format
Data Format: Delimited
Delimiter Format Type: Default CSV (ignores empty lines)
Header Line: With Header Line
Lines to Skip: 0
Em “Advanced Options”:
Parse NULLs: Deixar verdadeiro
NULL constant: Deixar vazio
Quando terminamos a configuração, ainda há alguns warnings, mas isso ocorre porque não destinamos o dado para lugar algum. Então é normal.
Agora, podemos adicionar o JDBC, que irá levar os dados para o MySQL.
Então vamos novamente em “Type to search” pesquisamos “JDBC producer” e adicionamos no pipeline.
Adicionamos os parâmetros abaixo:
General
Name: Ingestão
Description: Ingestão de dados no MySQL
JDBC
JDBC Connection String: jdbc:mysql://172.16.0.10:3306/COVID19
Table Name: T_CARGA_COVID
Também devemos habilitar as configurações avançadas, isso exibirá uma guia chamada “Advanced”.
Credentials
Username: root
Password: 12345
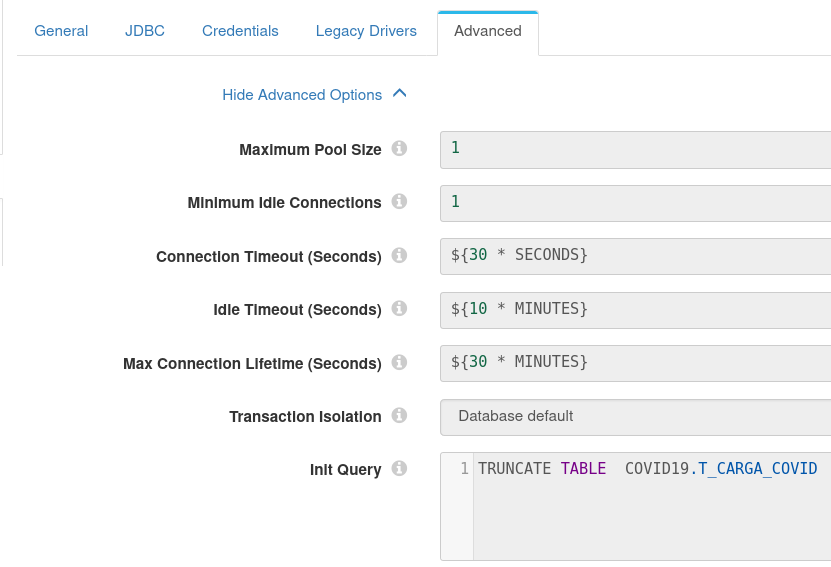
Advanced
Init Query: TRUNCATE TABLE COVID19.T_CARGA_COVID
Como a base de dados é completa, devemos primeiro limpar a tabela antes de realizar uma nova carga, então precisamos utilizar essa opção “Init Query” para fazer um truncate.
Termos o resultado abaixo:
Podemos observar que nos dois icones temos um circulo, então realizamos a ligação do Directory com o JDBC producer através dele, clicando no circulo do Directory e arrastando até o JDBC producer, ficando com o resultado abaixo:
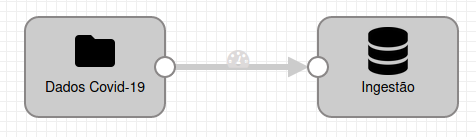
Nesse momento, não temos mais warnings em nosso pipeline, porém, precisamos realizar o upload do arquivo .jar do conector do MySQL.
Podemos baixar no seguinte link: https://dev.mysql.com/downloads/connector/j/
Depois de baixar, descompactamos, e na opção “External Libraries” do JDBC producer, realizamos o upload.
Pronto! Depois disso podemos fazer o “start” do pipeline.
O próprio Streamsets gera um dashboard sobre o processo, como você pode conferir abaixo:
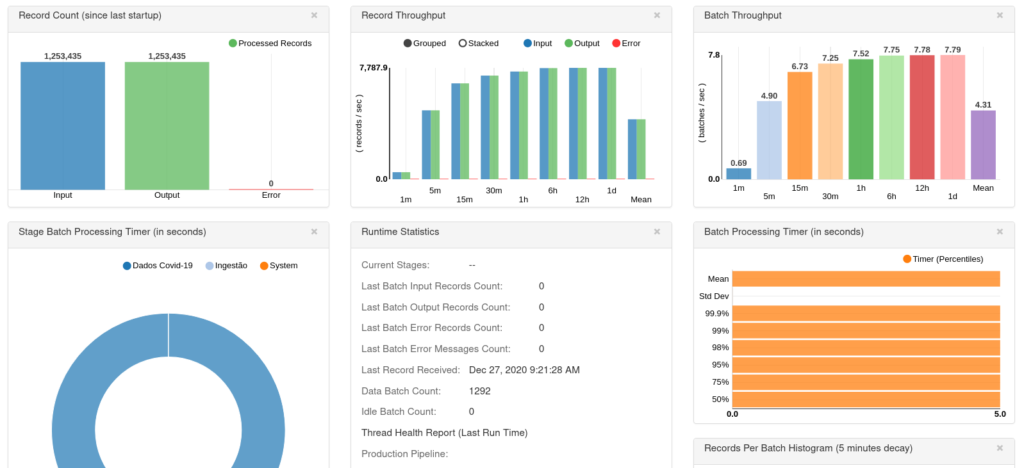
Se houver algum erro, poderemos ver no próprio gráfico. Como podemos observar, não tivemos erros no pipeline.
Importante: Essa tabela de carga contém tanto os dados consolidados por estado quanto os dados da cidade, então eu recomendo que a documentação seja lida antes de utilizar.
Documentação: https://github.com/turicas/covid19-br/blob/master/faq.md
Resumo
Nessa postagem fizemos:
- Criamos um contêiner rodando o MySQL.
- Criamos um volume para que os dados sejam persistidos.
- Criamos um arquivo de docker-compose para coordenar os contêineres e fixar o seus IP’s.
- Criamos um programa em shellscritp que realiza o download dos dados de COVID-19.
- Instalamos bibliotecas externas no Streamsets.
- Registramos a aplicação do Streamsets.
- Criamos um pipeline que lê um arquivo CSV de um diretório e carrega em uma tabela no MySQL (Processo de ingestão de dados).
Bastante coisa, não? 😀
O Streamsets é bem completo e podemos montar muitas opções de pipeline. Poderíamos buscar dados de um tópico Kafka, buscar de outro banco de dados, ler uma API, buscar dados de um servidor SFTP, entre outros…
Recomento que leiam a documentação que é bem rica.
Documentação: https://streamsets.com/documentation/controlhub/latest/help/controlhub/UserGuide/GettingStarted/DPM.html
No próximo post veremos como instalar e configurar o Apache Superset.
Então até lá! 🙂