Já ouviu falar do Streamsets? Não? E do Apache Superset? Também não?
Essas são ótimas opções para ter-se no ferramental de um engenheiro de dados, ainda mais quando falamos de ferramentas abertas!
A primeira ferramenta, Streamsets, é uma opção para ingestão de dados em batch e streaming, e que será abordada nessa primeira parte.
A segunda ferramenta, Apache Superset, é a opção da Apache para a visualização e exploração de dados. Ela é pouco conhecida, mas muito poderosa!
Motivação
Minha motivação aqui é criar um pipeline de dados completo, desde o consumo até a visualização dos dados.
Irei dividir esse pipeline em 4 partes.
Na primeira etapa irei instalar e configurar o Streamsets.
Na segunda etapa irei realizar a ingestão de dados em um banco de dados MySQL, utilizando o Streamsets.
Na terceira etapa irei instalar e configurar o Apache Superset.
Na ultima, irei consumir os dados de um banco MySQL, preparado na segunda etapa e então construir um dashboard com os dados.
Espero que gostem dessa serie, e caso tenham alguma sugestão, podem envia-la para contato@thedataengineer.com.br
O que é o Streamsets?
De forma resumida, o Streamsets é uma ferramenta de ingestão de dados onde podemos realizar o ETL tanto de dados em batch quanto de streaming.
Ele oferece uma interface super simples de utilizar e suas configurações são bem fáceis de se fazer.
Ele tem como pré-requisito o Java JDK 8.
Iremos realizar a instalação e configuração dessa ferramenta em um contêiner docker, que entendo ser uma maneira bem simples de testar a ferramenta, além de economizar um bom tempo com instalação de sistema operacional.
Caso você não queira ou não tenha familiaridade com o docker, você pode instalar uma distribuição linux no virtual box, a instalação ocorre da mesma maneira. 🙂
Bom, vamos lá!
Preparação do ambiente
Primeiro vamos fazer a preparação do ambiente em docker.
Caso você tenha escolhido instalar em uma maquina linux, deixarei o passo-a-passo no final da postagem.
Colocando de forma simples, podemos utilizar um Dockerfile com as configurações que queremos, assim como uma receita de bolo! E depois subir isso dentro de um contêiner docker.
Iremos utilizar uma imagem do Ubuntu, dentro dela configuraremos os passos necessários para a aplicação funcionar e um “entrypoint” para a execução do contêiner.
Abaixo nossas configurações do dockerfile.
FROM ubuntu:bionic
# Instalação de bibliotecas
RUN apt-get update -y && apt-get install -y ssh rsync net-tools vim openjdk-8-jdk wget
# Variável de ambiente do Java 8.
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Inclusão das informações no path
ENV PATH="/usr/lib/jvm/java-8-openjdk-amd64/bin:/opt/hadoop/bin:${PATH}"
# Diretório de trabalho
WORKDIR /opt
# Baixa a aplicação
RUN wget https://archives.streamsets.com/datacollector/3.18.1/tarball/activation/streamsets-datacollector-core-3.18.1.tgz
# Descompacta
RUN tar -xvzf streamsets-datacollector-core-3.18.1.tgz
# Renomeia a pasta
RUN mv streamsets-datacollector-3.18.1 streamsets
# Deleta arquivo
RUN rm streamsets-datacollector-core-3.18.1.tgz
# Executa a aplicação, "dc" significa "Data Collector"
ENTRYPOINT [ "/opt/streamsets/bin/streamsets","dc"]Agora vamos realizar o build do script acima.
Renomeei o arquivo como streamsets.dockerfile, com o comando abaixo podemos criar a imagem docker.
$ docker build -f streamsets.dockerfile . -t streamsetsAgora vamos criar um volume para a persistência dos dados do Streamsets, se não perderemos as alterações que fizermos no futuro, bem como também qualquer pipeline criado. 🙂
$ docker volume create streamsets-dataCriada a imagem e o volume, está na hora de executar o contêiner!
$ docker run -v streamsets-data:/opt/streamsets -d streamsetsCom isso, precisamos acessar o ip do contêiner. Primeiro listamos os contêineres em execução, para pegarmos o id do contêiner.
$ docker container lsIsso listará os contêineres em execução:
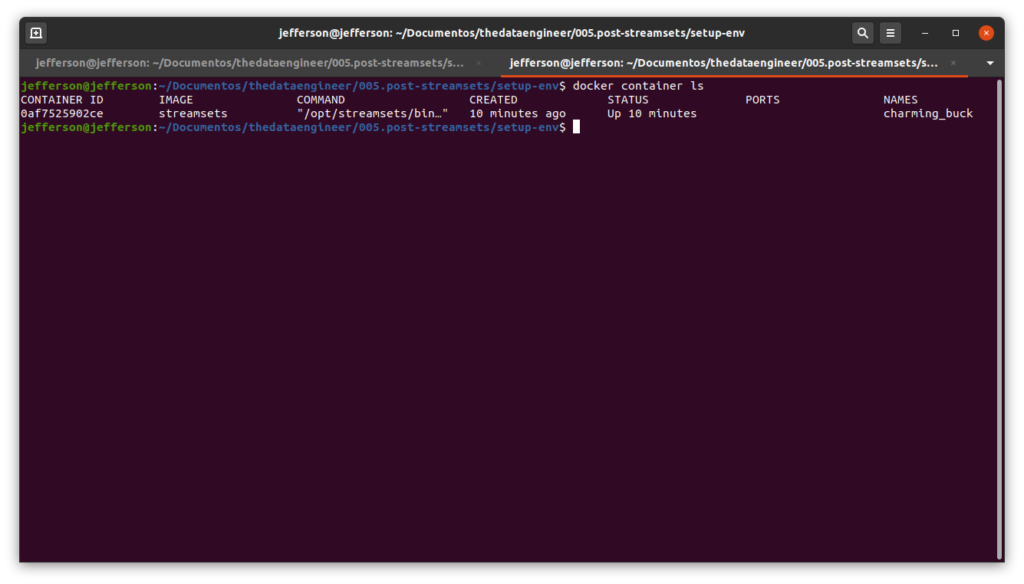
Agora, com posse do id do contêiner, localizado na coluna “CONTAINER ID”, podemos inspecionar o mesmo e buscar o ip.
$ docker container inspect 0af7525902ce | grep IPAddress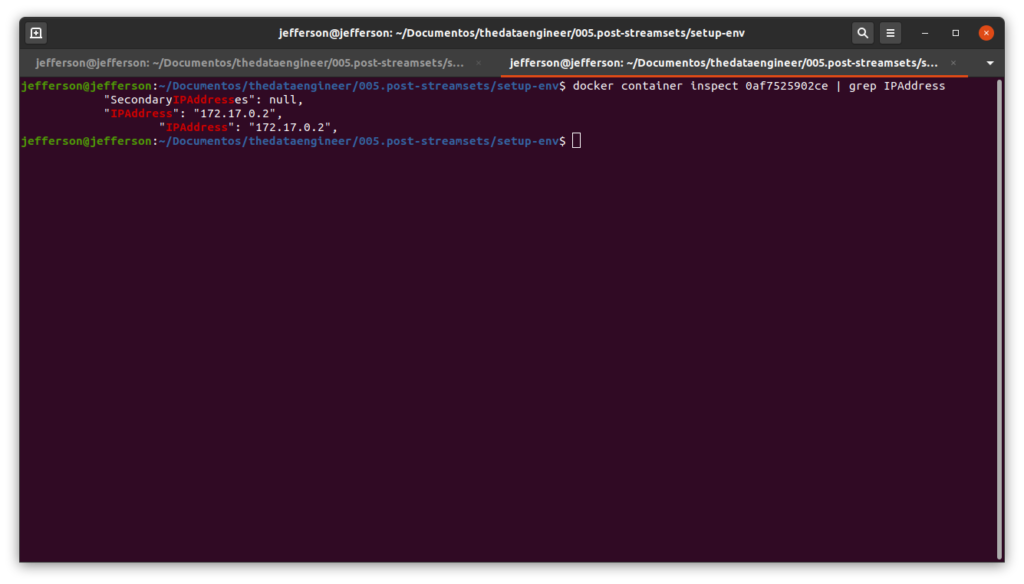
Em meu caso, o ip do contêiner é 172.17.0.2.
Então devemos acessar o seguinte endereço : ip-container:18630, onde roda a aplicação.
Abaixo o login padrão é admin e senha admin.
Depois teremos a tela inicial, para criarmos os pipelines de dados.
Instalando em uma máquina virtual
Instale uma distribuição do Ubuntu em uma maquina virtual, então no terminal dessa maquina você pode seguir os seguintes passos:
Aqui tem um vídeo que mostra como você pode fazer isso: https://www.youtube.com/watch?v=wGwikwPrACA
Primeiro deve-se instalar o Java JDK 8 e o wget.
$ apt-get install openjdk-8-jdk wget -yEu, particularmente, prefiro instalar minhas aplicações em /opt, mas pode-se fazer o download da aplicação no diretório de sua preferencia.
$ cd /opt
$ wget https://archives.streamsets.com/datacollector/3.18.1/tarball/activation/streamsets-datacollector-core-3.18.1.tgzDepois realizaremos a descompactação do arquivo, renomeação e remoção do arquivo compactado.
$ tar -xvzf streamsets-datacollector-core-3.18.1.tgz
$ mv streamsets-datacollector-3.18.1 streamsets
$ rm streamsets-datacollector-core-3.18.1.tgzAntes de iniciarmos a aplicação, vamos configurar a variável de ambiente do Java.
$ sudo "JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> /etc/environment
$ source /etc/environmentPara iniciar o Streamsets, digite o comando abaixo:
$ /opt/streamsets/bin/streamsets dcAgora, basta você pegar o ip da maquina virtual e seguir os passos de acesso.
Conclusão
Não existem muitas configurações a se fazer, basicamente devemos instalar o java, baixar a aplicação e executar seu binário.
Se você reparar no arquivo streamsets.dockerfile, basicamente são os passos para instalar o programa em uma maquina linux.
Na próxima etapa, onde faremos a ingestão de dados, teremos configurações mais interessantes, onde devemos instalar algumas coisas para podermos nos conectar com o banco destino.
Até o próximo tópico e espero que tenham gostado! 🙂