– Principais componentes – Modo de uso – Como isso conecta-se com Big Data
Certo, vamos começar?
Visão Geral
O Simple Storage Service ou S3, é um recurso da AWS para armazenarmos nossos dados. Ele já tem escalabilidade, alta disponibilidade, segurança e performance.
Além disso, o serviço é relativamente barato, fiz uma estimativa de quanto custariam armazenar 10TB por mês e recuperar esses mesmos 10TB.
O valor ficou em 242.69 USD
Veja como ficou minha simulação:
Unit conversions
- S3 Standard storage: 10 TB per month x 1024 GB in a TB = 10240 GB per month
- Data returned by S3 Select: 10 TB per month x 1024 GB in a TB = 10240 GB per month
Pricing calculations
Tiered price for: 10240 GB
10240 GB x 0.0230000000 USD = 235.52 USD
Total tier cost = 235.5200 USD (S3 Standard storage cost)
10,240 GB x 0.0007 USD = 7.168 USD (S3 select returned cost)
235.52 USD + 7.168 USD = 242.69 USD (Total S3 Standard Storage, data requests, S3 select cost)
**S3 Standard cost (monthly): 242.69 USD**
*** Simulação realizada 2023-10-11, Region: US East (Ohio)
Outro ponto interessante é que existem diversos tipos de S3, por exemplo, o Glacier, que é muito mais barato que o standard (simulado acima), pois nesse tipo de S3 espera-se que os dados não sejam acessados a todo o momento, nesse caso, os dados solicitados são disponibilizados após um tempo X pela Amazon.
Principais Componentes
Os principais componentes do S3 são:
Bucket – Um bucket é um container para o armazenamento dos objetos.
Nesse caso, é onde estão os servidores da Amazon. Esse item é bem importante, pois o preço pode variar de Region para Region, e existem outros elementos, como por exemplo a LGPD que em alguns casos pede que um tipo especifico de dados seja armazenado dentro do país.
Para criar um bucket, basta termos uma conta na AWS, você tem um período gratuito para uso, caso tenha interesse: Criar Conta
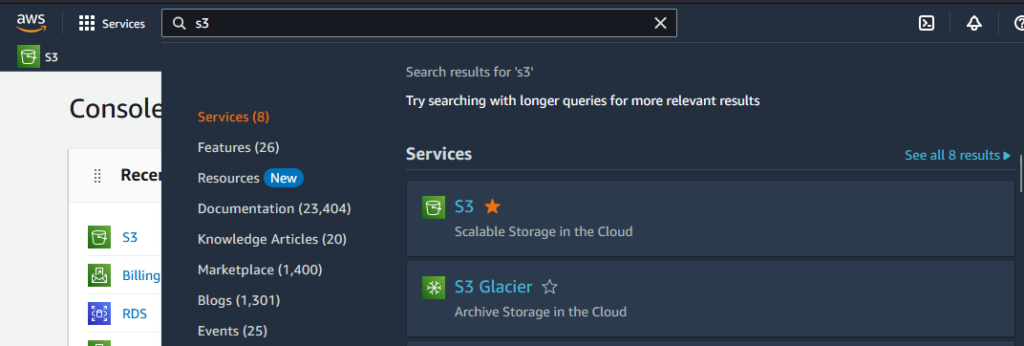
Dentro do console, fazemos uma busca por S3, o serviço será exibido:
Depois disso, entramos no serviço e ao lado teremos o botão Create Bucket:
A partir de agora são alguns poucos passos para criarmos nosso bucket.
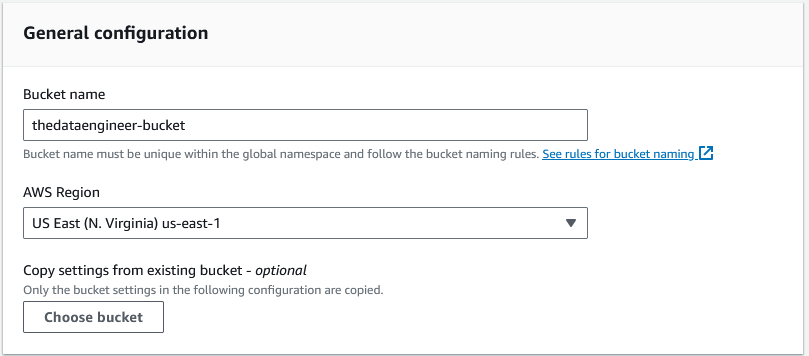
Primeiro escolhemos o nome para o bucket:
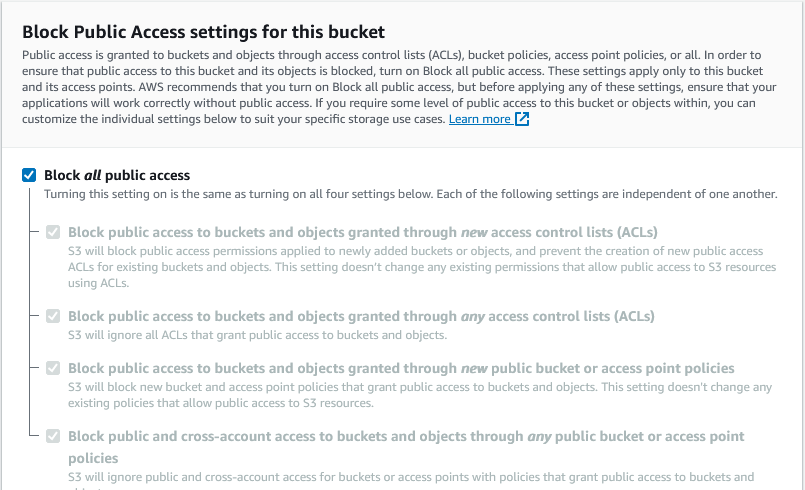
Aqui temos as políticas de acesso, no caso, todos os acessos públicos são bloqueados por padrão.
Feito isso, basta ir ao final da pagina e criarmos o bucket.
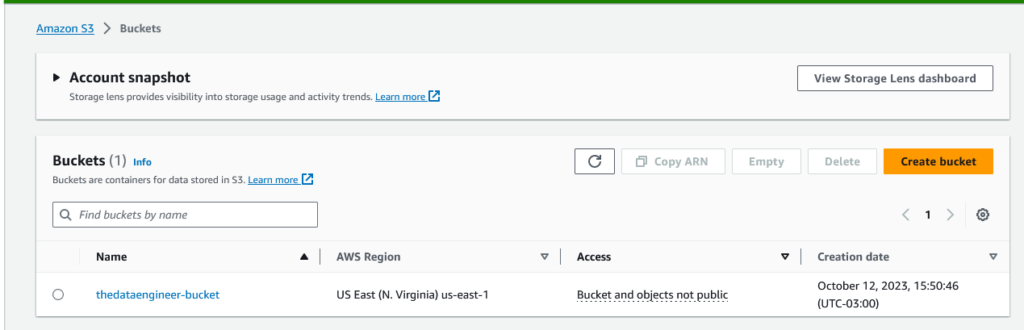
Depois, poderemos ver nosso bucket listado no S3.
Pronto! Já temos nosso bucket criado! 🙂
Modo de uso
Para o modo de uso, vou explicar de duas formas, a primeira, manualmente, utilizando o console da AWS e a outra usando um SDK da AWS em python chamado boto3.
O mais interessante é usarmos o boto3 para realizarmos nossas interações com nossos buckets, pois possibilita a automação de tarefas.
Vou usar alguns dados públicos sobre Consumidor.gov que é uma plataforma para resolução de conflitos por meio da internet.
Para realizar a carga manualmente é bem simples. Basta irmos no console da AWS > S3 e clicar no nosso bucket.
Depois disso, teremos 2 botões para UPLOAD, podemos utilizar qualquer um deles para realizar o upload.
Depois disso uma nova janela será apresentada, e nela temos a opção “Add files”.
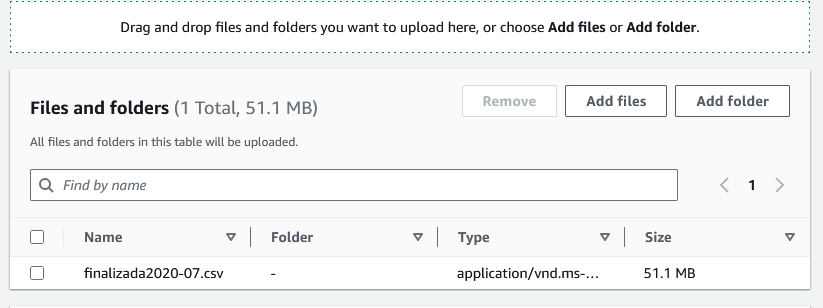
Quando clicamos nessa opção, podemos selecionar o arquivo na nossa maquina e ele será listado conforme a imagem abaixo:
Feito isso, teremos uma opção abaixo para upload.
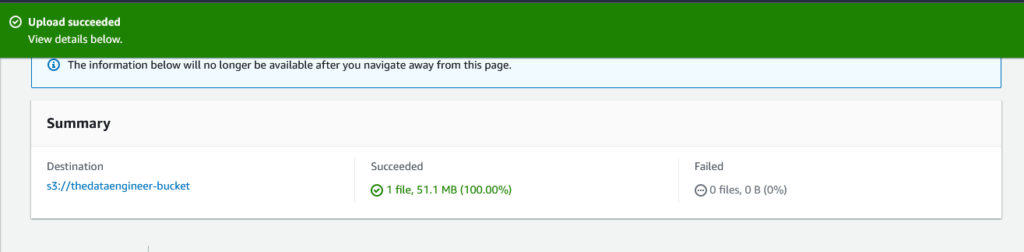
E o upload irá começar.
Uma vez concluída, teremos a seguinte informação de sucesso.
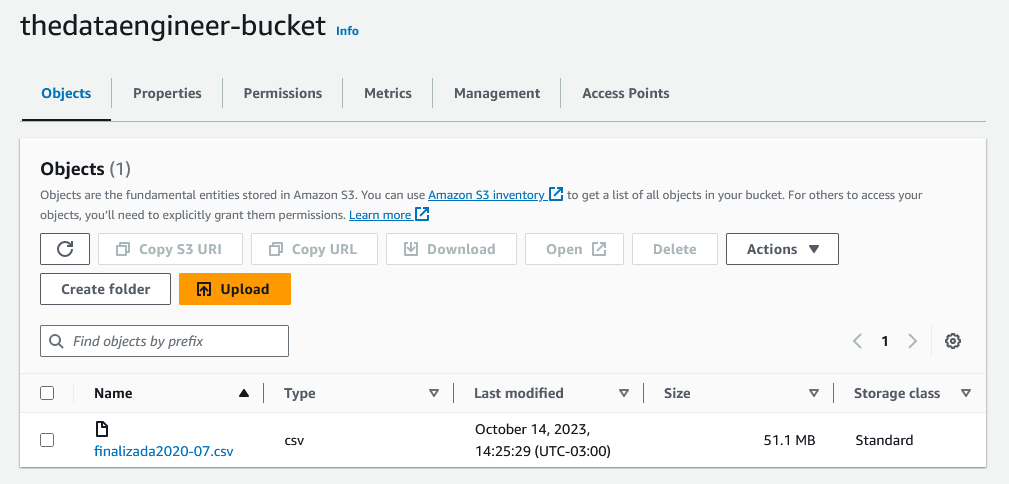
Quando voltamos para nosso bucket, podemos ver nosso arquivo disponível.
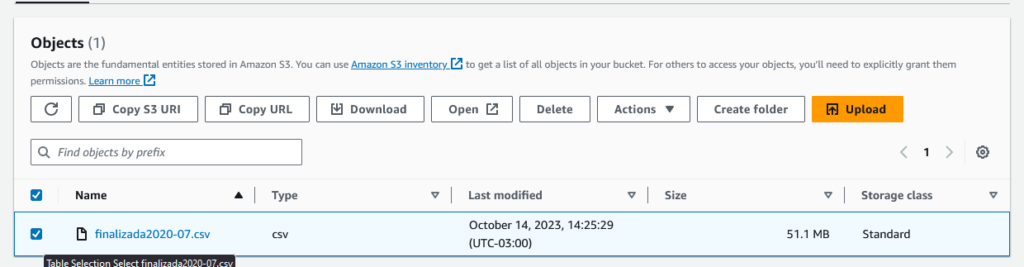
Para deletarmos o arquivo, podemos selecioná-lo e depois devemos ir na opção “Delete”.
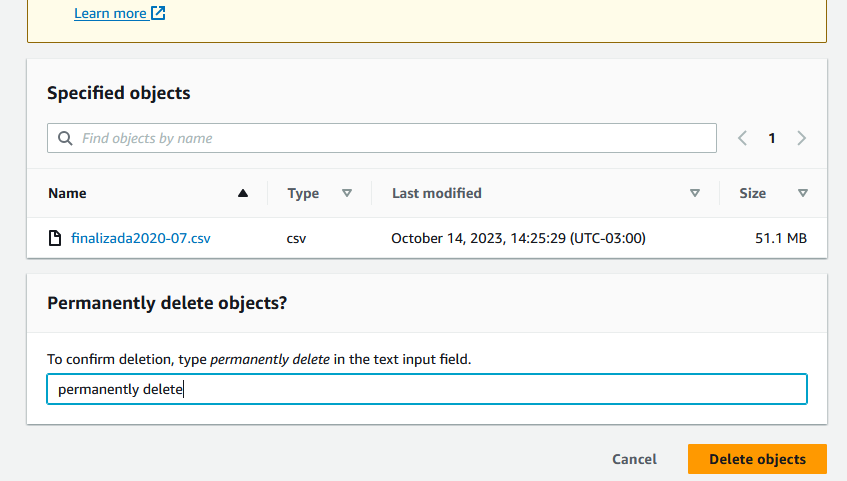
A seguinte tela será exibida onde temos que escrever “permanently delete” para o botão “Delete Objects” ser liberado e podermos efetivamente deletar o objeto.
Depois disso o objeto é deletado no nosso bucket.
Utilizando o SDK boto3
Para utilizar o boto3, precisamos nos autenticar de alguma forma na AWS. E existem algumas formas para fazer isso como instalando o aws-cli mas escolhi gerar as credencias via IAM.
Lá também há uma documentação de como realizar a preparação do ambiente e configurar o arquivo de configuração com as credencias da AWS.
Certo, bora começar!
Primeiro, vamos criar uma credencial.
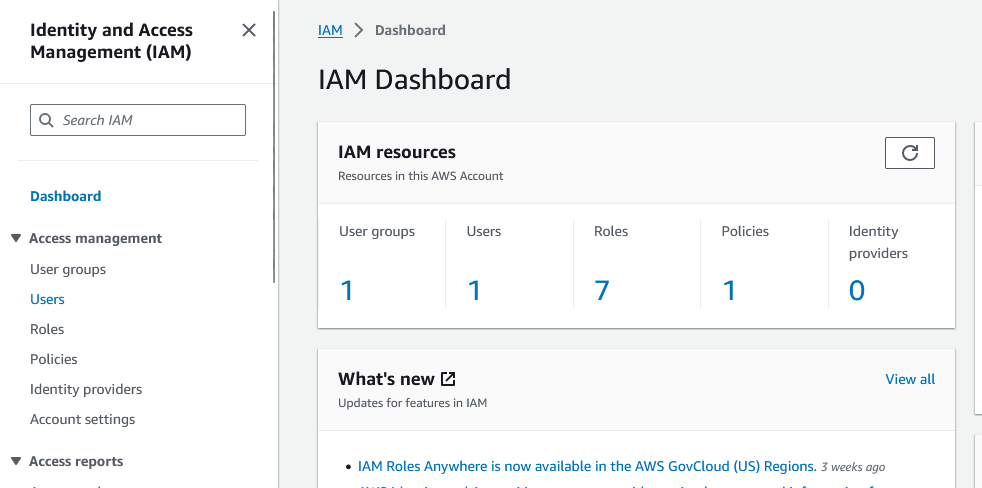
No console da AWS, procure o serviço chamado IAM, depois de acessar, teremos uma tela conforme a tela abaixo:
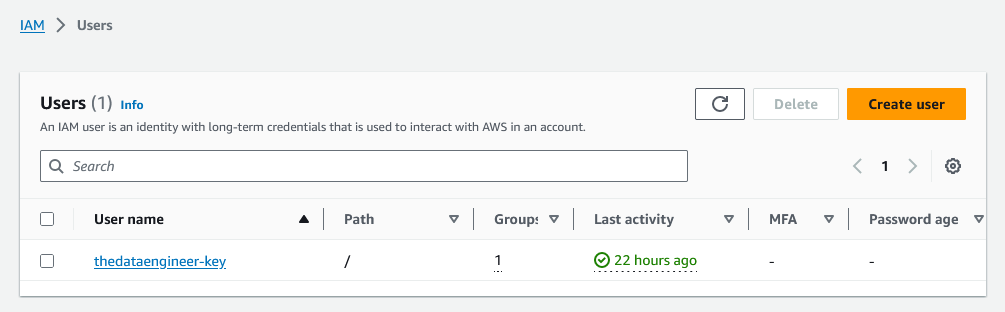
Feito isso, devemos clicar em “Users”, entraremos na tela abaixo:
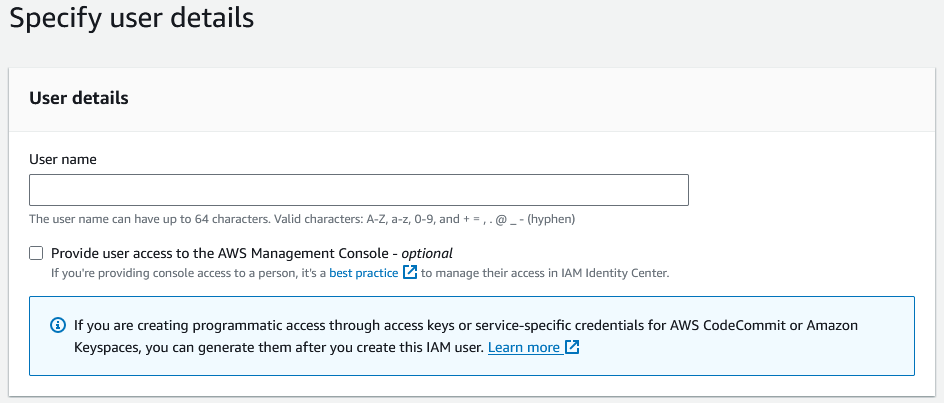
Agora, precisaremos criar um usuário novo. Clique em “Create user”. Podemos inserir o nome do usuário desejado no campo “User name”.
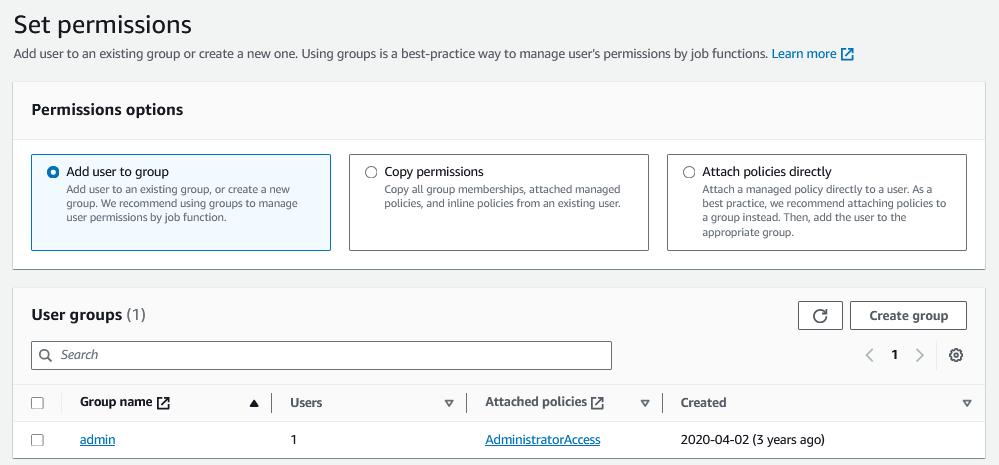
Depois disso, podemos ir para o próximo passo, incluir um grupo de permissão.
No caso, eu vou usar o grupo de administrador, isso para facilitar nosso exercício aqui, mas existem maneira mais refinadas limitando os poderes do usuário.
Selecionado o grupo, podemos fazer uma revisão final e clicar em “Create user”.
Feito isso, podemos voltar para a tela de Users e clicar no usuário criado.
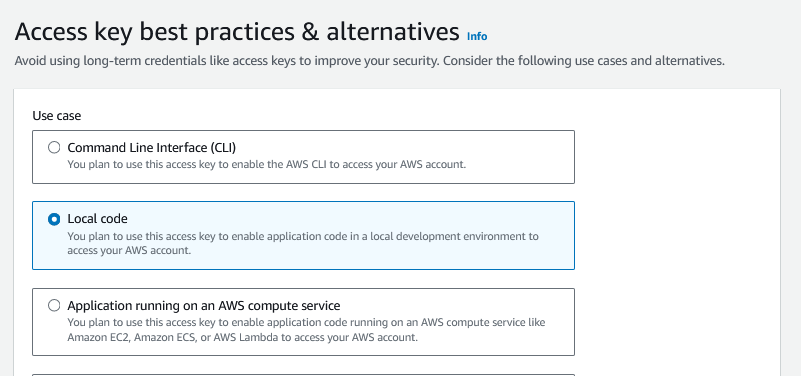
Logo no canto direito temos a informação “Create access key”, o que abrirá a tela baixo, onde devemos selecionar a opção “Local code”.
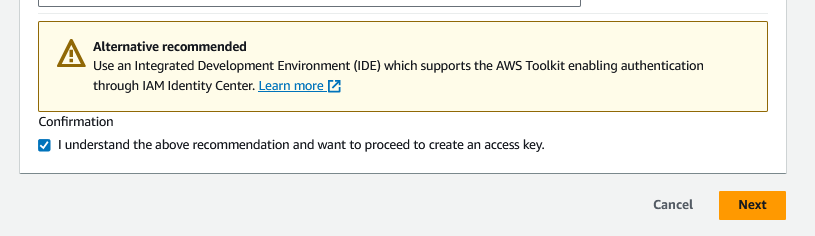
Nesse momento, a AWS mostra que há uma outra alternativa para usarmos ao invés das chaves, em nosso caso, podemos selecionar que entendemos e ir para a próxima etapa.
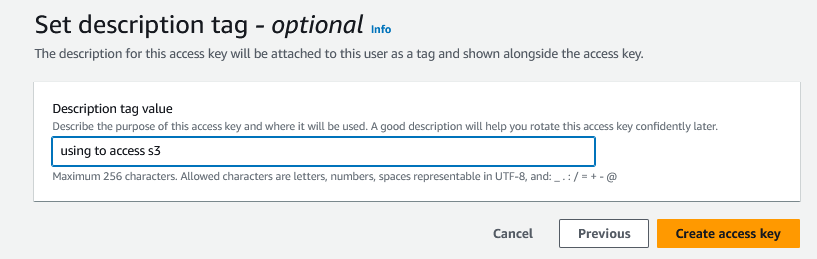
Agora devemos colocar uma breve descrição da chave (opcional):
Nesse momento, nossas chaves são criadas, e devemos copia-las ou baixa-las.
**Tomem cuidado com as chaves, principalmente com expor essas credenciais em repositórios públicos como o github**
Agora que passamos do passo da criação das nossas chaves, deixei no código um arquivo de configuração onde essas chaves devem ser inseridas.
[aws-credentials]
ACCESS_KEY=<Insira sua ACCESS_KEY>
SECRET_KEY=<Insira sua SECRET_KEY>
Feito isso, estamos prontos para usar o boto3 com o python.
Todos o códigos estão disponíveis no repo já citado, vou mais é explicar cada uma das funções, quebrando o código em varias partes.
Nessa primeira parte, apenas usamos as credencias geradas para se autenticar na AWS com nossa conta e usar o serviço do s3.
if __name__ == '__main__':
print('Listing files')
response = s3.list_objects(Bucket='thedataengineer-bucket')
for file in response['Contents']:
print(file)
Esse caso realiza o download de um arquivo para maquina local.
Como parâmetros passamos na seguinte ordem:
1. Nome do bucket. 2. Nome do arquivo que está no bucket. 3. Onde ele deverá ser salvo.
if __name__ == '__main__':
print('Download File')
s3.download_file('thedataengineer-bucket', 'finalizada2020-07.csv', 'downloaded\\finalizada2020-07.csv')
O ultimo caso é como deletar um arquivo.
Nesse caso, passamos:
1. Nome do bucket. 2. Nome do arquivo.
if __name__ == '__main__':
print('Delete File')
s3.delete_object(Bucket='thedataengineer-bucket', Key='finalizada2020-07.csv')
Ainda há a possibilidade de criarmos buckets usando o boto3 e muito mais coisas, acho que vale uma olhada na documentação, pois as opções são bem ricas, tentei listar apenas as principais.
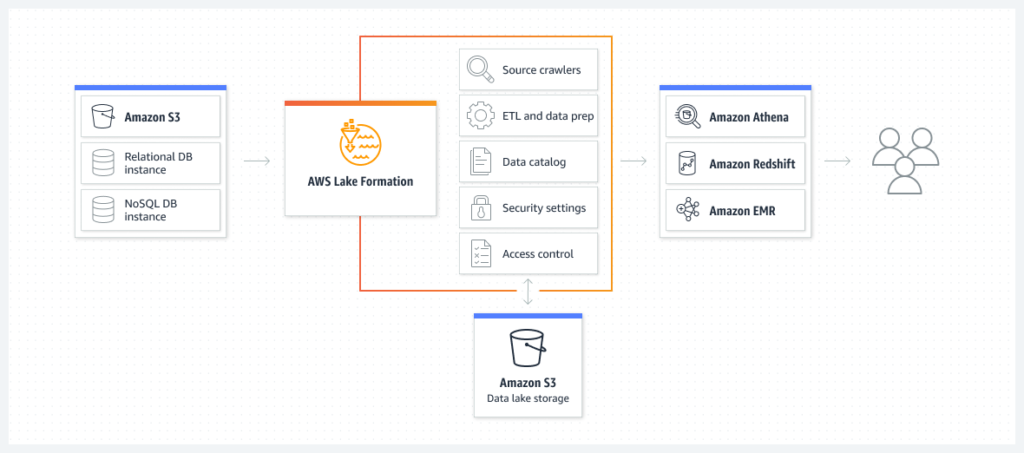
Como isso conecta-se com o Big Data
Um dos usos mais comuns dentro de Big Data para o S3 é a construção de Data Lakes, pois, vejam todas as vantagem que temos:
Escalabilidade
Alta disponibilidade
Segurança
Performance
São todos os requisitos que precisamos para um Data Lake, certo? 🙂
Espero que tenham gostado do conteúdo e que ele tenha alguma utilidade para você. Particularmente, eu acho o s3 um recurso incrível e muito utilizado hoje em dia, além da facilidade de usar um SDK para tornar as coisas mais automáticas e fáceis pra gente.
Para além disso, ganhamos muito tempo usando o s3 na AWS é um recursos perfeito para data lakes dadas suas características.
Na ultima parte do nosso pipeline iremos finalmente utilizar os dados da ingestão feita via Streamsets para alimentar uma aplicação de visualização de dados, no caso, o Apache Superset, instalado na ultima postagem. Sem mais Leia mais