Olá! Sou Jefferson. Trabalho com: Dados, Dashboards, SQL, SAS, Python e muito mais! Criei esse cantinho para postar alguns conhecimentos. :)

Salve, pessoal! Tudo certo? Espero que sim! Estava ouvindo um podcast sobre gerenciamento de projetos que acompanho há alguns bons anos (para quem tiver curiosidade é o 5 Minutes Podcast do Ricardo Vargas), nesse episódio Leia mais

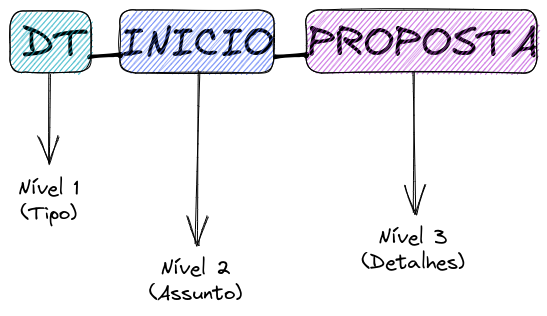
Essa postagem mostra o que é tokenização, a diferença entre criptografia e tokenização. E como podemos aplicar uma tokenização à nossos dados.

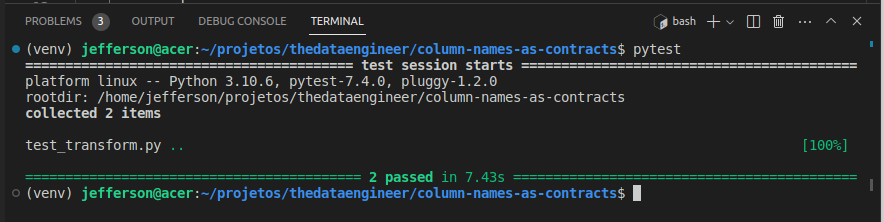
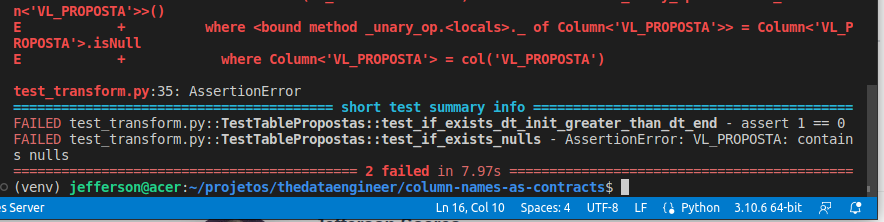
Fala, pessoal! Tudo certo? Espero que sim! Esses dias em uma conversa, foi-me apresentado um certo problema: “Como realizar o processamento de dados que nem o criador do pipe pode visualizar?”. Isso ficou em minha Leia mais