Fala, pessoal!
Tudo certo? Espero que sim!
Há algum tempo, uma colega perguntou a diferença de tokenização e criptografia.
Achei que seria interessante trazer esse tema aqui, pois deve ser uma duvida que ocorre frequentemente.
Então let’s go! 😀
Tokenização e Criptografia
Basicamente, a tokenização de dados é criptografia, no caso, uma das técnicas de criptografia o hash.
No final das contas o objetivo é o mesmo:
Esconder o dado real.
Quando aplicamos um hash à um dado, o algoritmo embaralha o dado de modo que ele não pode ser entendido e esse algoritmo de hash não pode ser revertido.
Alguns dos algoritmos de hash são:
- MD5
- SHA-1
- SHA-2
- SHA-256
É importante entender a entropia do dado em que se quer aplicar o hash, pois dados de baixa entropia como: cpf, rg, matriculas sequenciais e etc são fáceis de descobrir, pois há um padrão de criação conhecido.
Ex.:
O CPF tem um padrão de criação definido, é uma sequencia de números limitada e que contém um validador para saber se o CPF é valido ou não.
Dessa forma, existe uma maneria de criarmos um “de/para” de CPF’s validos, passarmos os principais algoritmos de hash conhecidos e cruzar com a base tokenizada a fim de saber qual era o dado original.
Para evitarmos tal problema, nesses casos é importante aplicar também o que chamamos de salt, que tem por objetivo aumentar o nível de entropia do dado para que não seja tão simples descobrir seu conteúdo original.
Um pouquinho de código
Criei uma função em python realiza o md5 em uma string.
Coloquei como input o valor: “thedataengineer.com.br“.
Como resposta obtive o hash: “18af859553793025d0891c7d2c726e50”
import hashlib
def hash_md5(string_to_hash: str) -> str:
return hashlib.md5(string_to_hash.encode()).hexdigest()
if __name__ == '__main__':
print(hash_md5("thedataengineer.com.br"))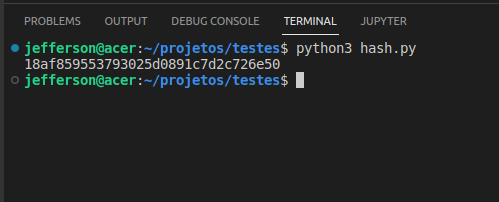
Certo, e como faríamos em casos onde a entropia do dado é baixa?
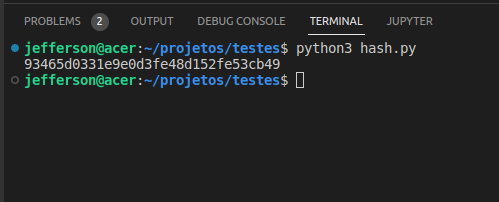
Para isso, modifiquei um pouco a função para receber o “salt” que aumentará o nível de entropia.
Então para o mesmo input, tenho um resultado diferente, impossível de se saber sem que o salt “vaze” de alguma forma.
Novo resultado: “93465d0331e9e0d3fe48d152fe53cb49”
import hashlib
def hash_md5(string_to_hash: str, salt: str) -> str:
string_to_hash_with_salt = string_to_hash + salt
return hashlib.md5(string_to_hash_with_salt.encode()).hexdigest()
if __name__ == '__main__':
print(hash_md5("thedataengineer.com.br", "foo"))
Conclusão
Espero que tenham gostado da postagem e que ela ajude de alguma forma no seu dia a dia.
É bem importante prestarmos atenção na entropia do dado quando falamos de tokenização e também guardar a regra de salt à 7 chaves.
Por hoje é isso, pessoal!
Até a próxima!
😀
