Salve, pessoal!
Tudo certo?
Hoje trarei uma introdução sobre Open Table Format, que são formatos de tabela que usamos em nossos Data Lakehouse.
Esses formatos trazem diversos benefícios para nossa arquitetura, como evolução de schema, transações ACID e versionamento, além de outros.
Porquê deveríamos usar esses formatos
Citei alguns dos benefícios que esses formatos trazem para campo, e cada um deles está atrelado à algum problema.
Transações ACID
Vamos começar falando de transações ACID nos bancos de dados tradicionais, as transações ACID garantem:
- Atomicidade: quando você “pede” para o banco de dados realizar a leitura de uma tabela, a gravação em outra e ao mesmo tempo a inserção de novos dados, essa transação tratada de forma atômica, ou seja, como algo único. Logo, ou todas as instruções dão certo, ou nada dá certo.
- Consistência: garante que as tabelas sejam alteradas de maneira previsível, garantindo que as tabelas continuem íntegras mesmo depois de erros.
- Isolamento: diversos usuários podem ler e gravar dados ao mesmo tempo, pois o isolamento garante que uma transação não interfira na outra. Na prática, é como se cada usuário estivesse rodando a transação de forma independente.
- Durabilidade: garante que transações que tiveram êxito sejam armazenadas mesmo em caso de erros de sistema.
Imagine que você tem muitos usuários escrevendo em uma tabela em seu data lake, essas coisas me parecem bem importantes de se garantir.
Controle de versão
No mundo de engenharia de software, os engenheiros muitas vezes trabalham em cima da mesma base de código, e nessa situação precisamos saber qual versão do código é a mais atual.
Para conseguir tal coisa, os engenheiros utilizam o git como ferramenta de versionamento, criando seus ramos de desenvolvimento e realizando commits de suas alterações para o código em produção.
Usando o git, pode-se rapidamente comparar alterações de código ou mesmo realizar o rollback para uma versão anterior do código. Dessa forma podemos manter apenas uma versão em nossa branch de produção.
O versionamento para os dados segue o mesmo princípio, saber qual a última versão de um determinado dado. Sendo um analista, cientista ou engenheiro de dados, saber qual é a fonte da verdade é muito importante, principalmente quando chega algum questionamento.
Saber qual versão do dado foi usada para uma análise ou mesmo um modelo irá deixar o processo de debug muito mais simples.
Evolução de schema
Como sabemos, uma característica permanente da nossa área é a mudança. Isso implica que nossas tabelas irão mudar necessariamente.
Um formato de tabela que permita a evolução do schema de forma menos dolorosa é uma característica importante de se considerar.
Ajustar tipos de dados ou criar novas colunas são tipos de evolução de schema.
Validação de schema
Por outro lado, precisamos em certas circunstâncias, não permitir a mudança de schema. Principalmente quando falamos de usuários não especializados que podem por acidentes acabar mudando o schema ou trazendo erros para dentro de uma tabela.
Então uma tecnologia que também permita a criação de regras mais rígidas também é importante.
Principais players
Atualmente temos três principais Open Table Format no mercado.
- Apache Iceberg
- Apache Hudi
- Apache Hive
- Delta Lake
Cada um tem em suas tecnologias os pontos abordados acima, mesmo que parcialmente, além de outras features.
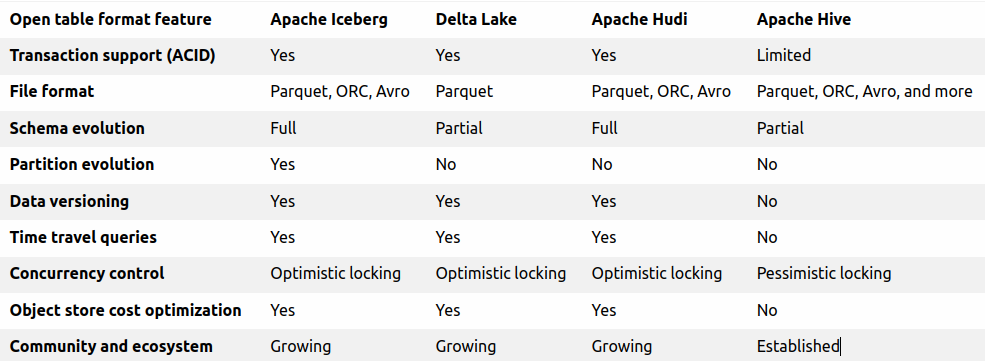
Abaixo temos um comparativo de cada uma:
Conclusão
Essa é uma breve introdução sobre Open Table Format.
Entendemos as motivações para o uso da tecnologia, os principais players e um comparativo de cada um deles.
Para os próximos passos, irei mostrar essas tecnologias em uso, pretendo começar com o Apache Iceberg.
Nos vemos lá!
Um abraço!