Olá! Sou Jefferson. Trabalho com: Dados, Dashboards, SQL, SAS, Python e muito mais! Criei esse cantinho para postar alguns conhecimentos. :)
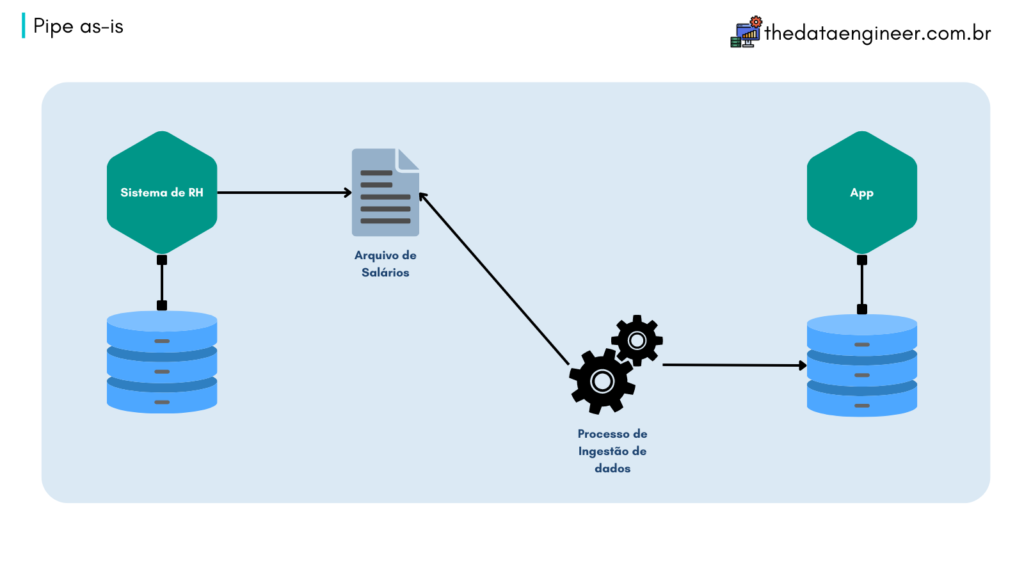
Essa postagem tem como intuito introduzir a ferramenta de ingestão de dados Apache Flume

Fala pessoal! Tudo certo? Conhecem o Apache NiFi? Ele é uma das ferramentas da Apache que apoiam o big data stack, na parte de ingestão de dados! A ferramenta é bem fácil de usar, pois Leia mais

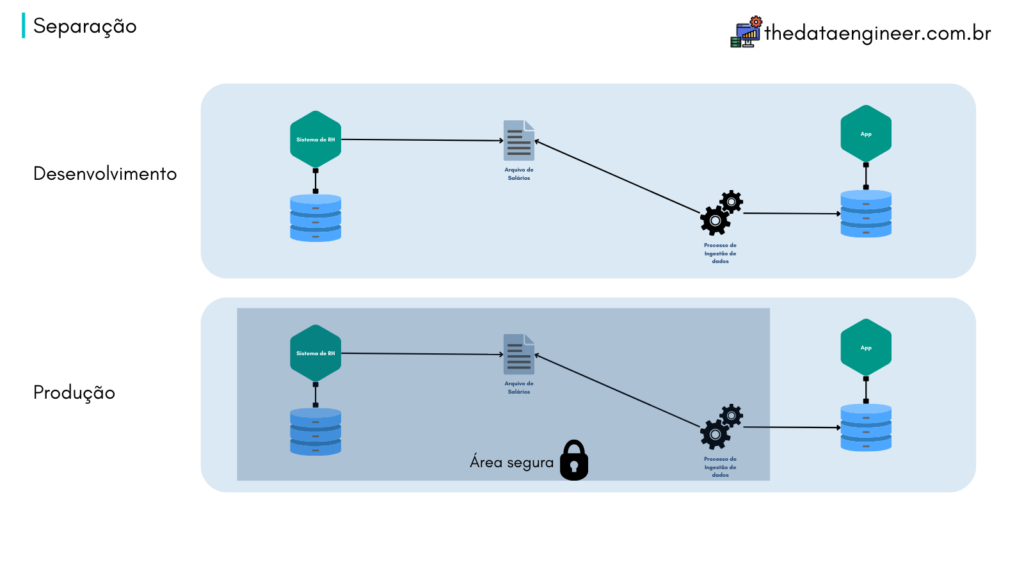
Continuando a serie do pipeline de dados, agora iremos fazer a preparação do ambiente em MySQL e realizar o processo de ingestão de dados com o Streamsets. Nessa etapa iremos adicionar dois novos itens em Leia mais