Fala, pessoal! Tudo certo?
Espero que sim!
Hoje irei demonstrar o funcionamento do Apache Flume, uma ótima ferramenta para movimentação de grandes quantidades de dados!
Espero que gostem! Pois é uma ferramenta bem legal! 🙂
O que é o Apache Flume?
Segundo a descrição da própria Apache (descrição), podemos entender que o Apache Flume é um sistema distribuído, confiável e com alta disponibilidade para: coletar, agregar e mover grandes quantidades de dados para uma fonte centralizada.
Isso faz com que ele seja uma ótima ferramenta para usarmos em ingestão de dados.
E faremos dois exemplos nessa postagem.
Arquitetura básica do Apache Flume
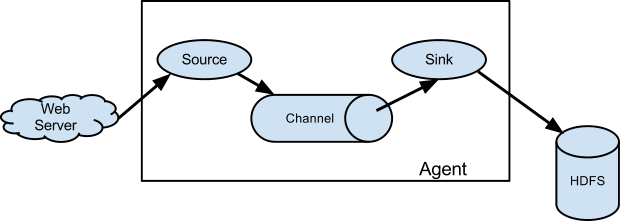
O Apache Flume tem 4 componentes principais, são eles:
- agent
- Componente principal que contem a configuração do fluxo.
- source
- Onde podemos configurar a entrada dos dados.
- channel
- Onde podemos configurar por onde os dados passam. (memória, disco ou um híbrido dos dois).
- sink
- Onde iremos armazenar esses dados.
Abaixo, temos um desenho retirado da documentação que ilustra bem como os componentes interagem.
O que iremos fazer nessa postagem são criar 2 agentes.
O primeiro irá atuar como um “file watcher” que irá monitorar um diretório, movendo o conteúdo de arquivos para arquivos dentro de uma outra pasta.
O segundo irá armazenar requisições HTTP do tipo POST em um arquivo, poderemos testa-lo utilizando o Postman.
Instalando o Apache Flume
Para instalar o Apache Flume, basta baixarmos o arquivo binário para um diretório e descompacta-lo.
Arquivo: https://dlcdn.apache.org/flume/1.10.0/apache-flume-1.10.0-bin.tar.gz
Como requisito, precisamos ter o Java instalado (8 ou superior) e ter a variável de ambiente JAVA_HOME com o caminho dos arquivos do Java.
Configurando nossos agentes
Bom, agora criaremos a configuração de nossos agentes! 🙂
Vou criar dois arquivos dentro da pasta “conf” do Apache Flume.
- agente-file-watcher.conf
- agente-http-post.conf
Poderíamos colocar todos em um mesmo arquivo, mas optei por separa-los, pois entendo ficar mais organizado.
Agente 1 (File Watcher)
Para a source, utilizaremos o Spooling Directory Source que irá servir de file watcher observando um diretório.
Para o channel, utilizaremos o Memory Channel para armazenar os dados apenas na memória.
Para o sink, utilizaremos o File Roll Sink que armazenará os dados em outro diretório.
Como podem ver, no arquivo abaixo, nosso agente monitorará a pasta que está indicada no spoolDir e gravará os dados na pasta indicada no sink.directory.
# geral
agente1.channels = channel-file-wacther
agente1.sources = source-file-wacther
agente1.sinks = sink-file-wacther
# source
agente1.sources.source-file-wacther.type = spooldir
agente1.sources.source-file-wacther.channels = channel-file-wacther
agente1.sources.source-file-wacther.spoolDir = /home/jeffersons/projects_/apache-flume/apache-flume-1.10.0-bin/data/source
agente1.sources.source-file-wacther.fileHeader = true
# channel
agente1.channels.channel-file-wacther.type = memory
agente1.channels.channel-file-wacther.capacity = 10000
agente1.channels.channel-file-wacther.transactionCapacity = 10000
agente1.channels.channel-file-wacther.byteCapacityBufferPercentage = 20
agente1.channels.channel-file-wacther.byteCapacity = 800000
# sink
agente1.sinks.sink-file-wacther.type = file_roll
agente1.sinks.sink-file-wacther.channel = channel-file-wacther
agente1.sinks.sink-file-wacther.sink.directory = /home/jeffersons/projects_/apache-flume/apache-flume-1.10.0-bin/data/target
agente1.sinks.sink-file-wacther.sink.rollInterval = 0Agente 2 (Http Post)
Para a source, vamos usar o HTTP Source, que irá receber requisições do tipo POST.
O channel e sink serão do mesmo tipo do agente 1.
O arquivo abaixo tem as configurações de nosso segundo agente.
# geral
agente2.channels = channel-http-post
agente2.sources = source-http-post
agente2.sinks = sink-http-post
# source
agente2.sources.source-http-post.type = http
agente2.sources.source-http-post.port = 5140
agente2.sources.source-http-post.channels = channel-http-post
agente2.sources.source-http-post.HttpConfiguration.sendServerVersion = false
agente2.sources.source-http-post.ServerConnector.idleTimeout = 300
# channel
agente2.channels.channel-http-post.type = memory
agente2.channels.channel-http-post.capacity = 10000
agente2.channels.channel-http-post.transactionCapacity = 10000
agente2.channels.channel-http-post.byteCapacityBufferPercentage = 20
agente2.channels.channel-http-post.byteCapacity = 800000
# sink
agente2.sinks.sink-http-post.type = file_roll
agente2.sinks.sink-http-post.channel = channel-http-post
agente2.sinks.sink-http-post.sink.directory = /home/jeffersons/projects_/apache-flume/apache-flume-1.10.0-bin/data/target-post
agente2.sinks.sink-http-post.sink.rollInterval = 0Testando o fluxo
Agora que nossos arquivos estão prontos, vamos realizar o teste dos nossos agentes.
Agente 1
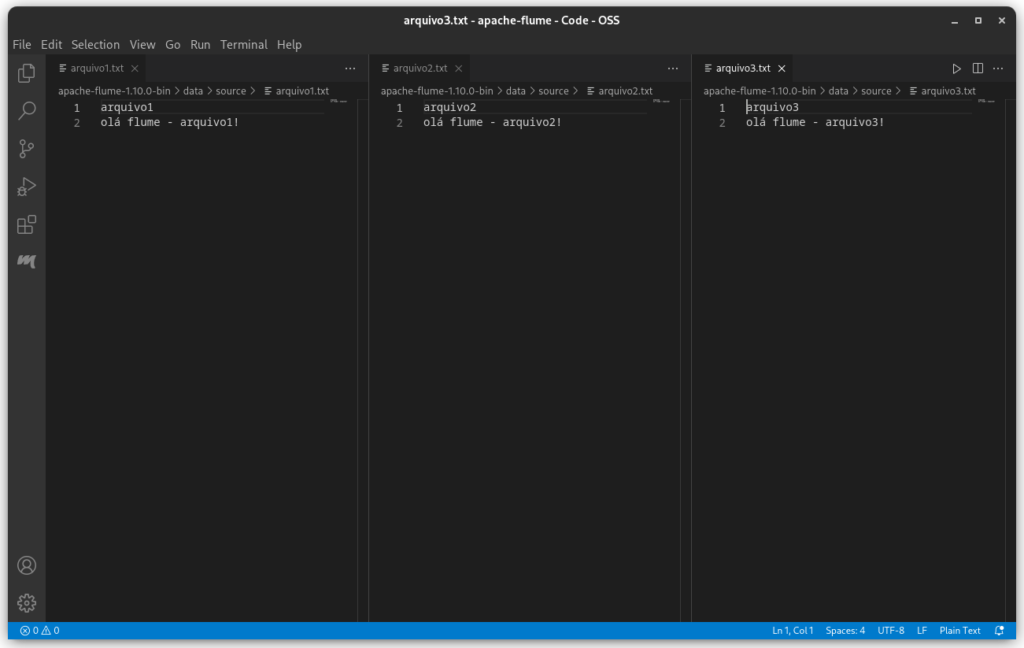
Primeiro, vamos criar alguns arquivos de texto no diretório source com algum texto.
Agora, dentro da pasta do Apache Flume, vamos iniciar o agente com o comando abaixo :).
bin/flume-ng agent --conf ./conf/ -f conf/agente-file-watcher.conf -Dflume.root.logger=DEBUG,console -n agente1
Teremos como resultado a saída abaixo:
Além disso, poderemos verificar que na pasta onde estamos foi gerado um arquivo chamado flume.log.
Agora, na pasta target, poderemos ver os dados consumidos em um único arquivo.
E na pasta source, os arquivos que foram consumidos agora em o final “.COMPLETED“.
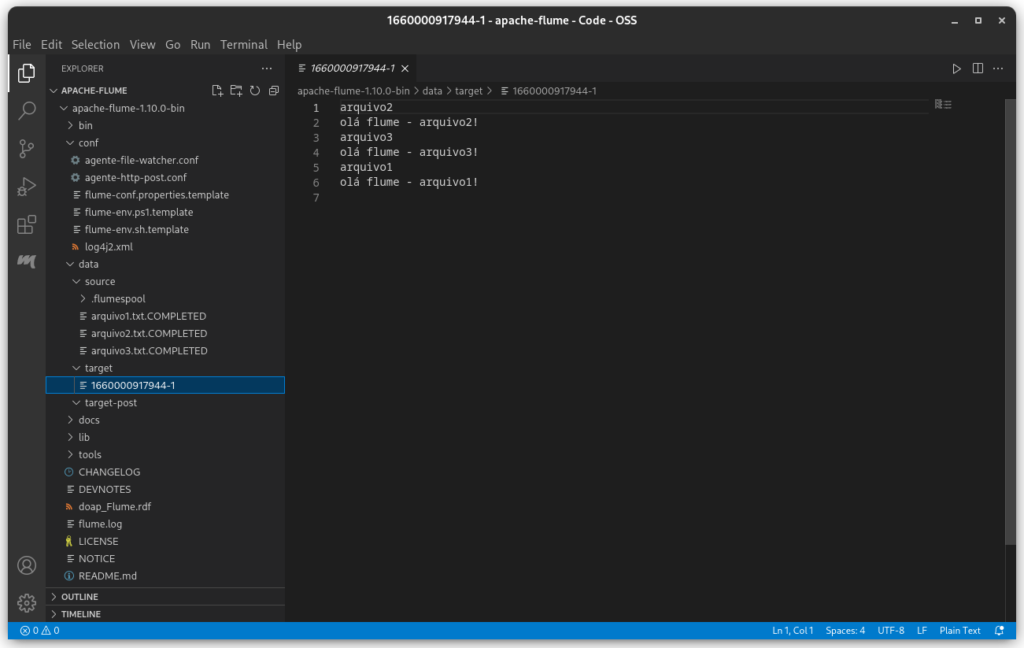
Bem legal, né? B)
Agente 2
Para o agente 2, iremos usar o Postman para fazer uma requisição HTTP do tipo POST.
O detalhe é que a mensagem dever ir na chave com o nome de “body” na requisição, outro ponto é que a aplicação espera um array de json.
[
{
"body" : "mensagem 1"
},
{
"body" : "mensagem 2"
},
{
"body" : "mensagem 3"
},
{
"body" : "mensagem 4"
}
]Vamos iniciar nosso agente com o comando abaixo:
bin/flume-ng agent --conf ./conf/ -f conf/agente-http-post.conf -Dflume.root.logger=DEBUG,console -n agente2A saída abaixo deve ser exibida:
Agora vamos enviar nossa requisição via Postman:
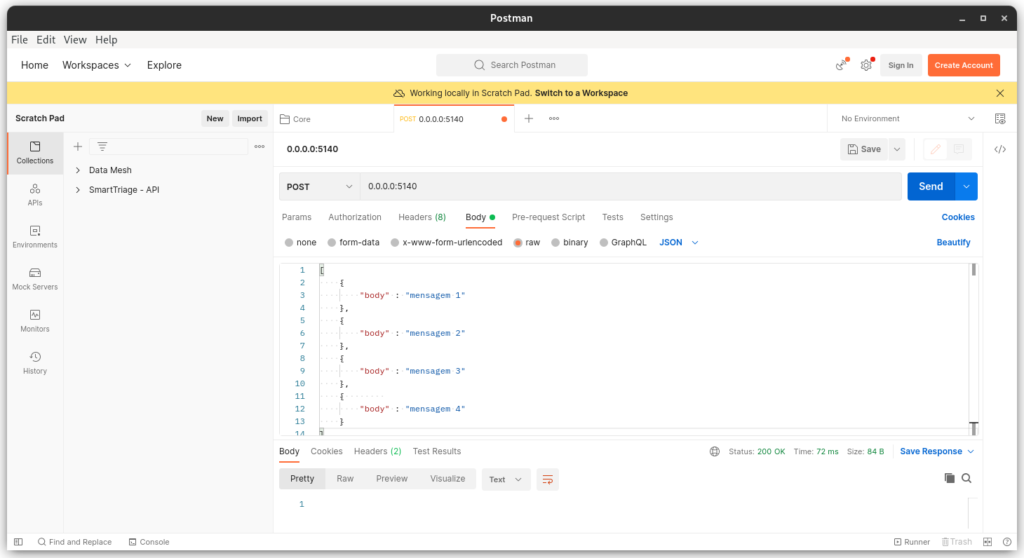
Note que o status code 200 é retornado, indicando o sucesso no envio das informações.
Podemos ver no target-post o arquivo com as mensagens enviadas.
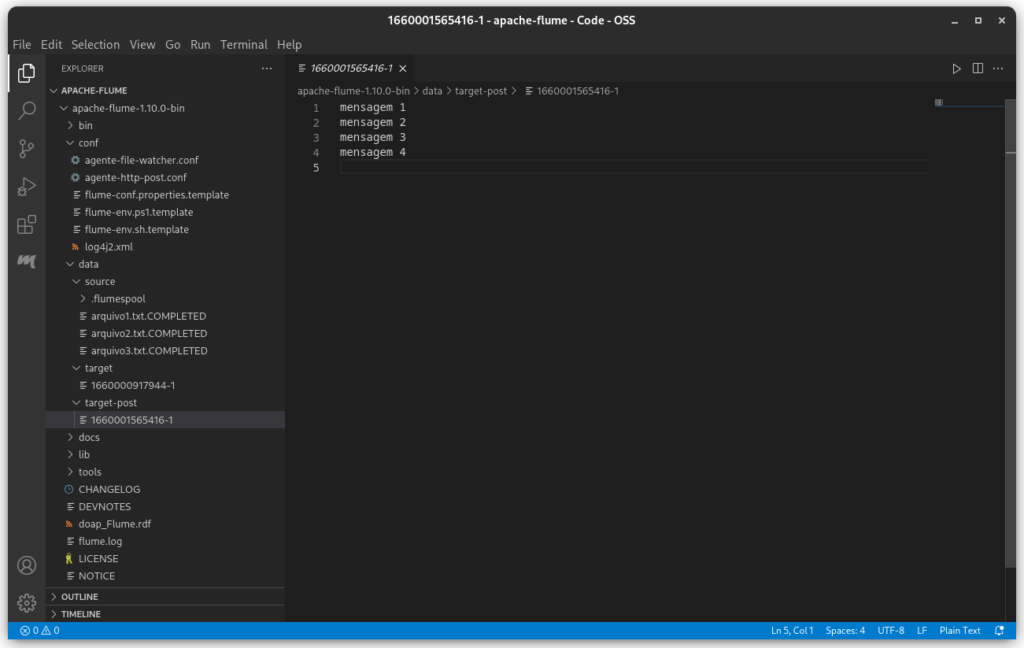
Show! 🙂
Conclusão
O Apache Flume é uma ferramenta bem legal! Se você quer mover uma grande quantidade de dados, acho que vale a pena estuda-la um pouco mais. 🙂
Espero que tenham gostado da postagem!
Um abraço!
Docs:
https://cwiki.apache.org/confluence/display/FLUME/Getting+Started
https://flume.apache.org/FlumeUserGuide.html