Olá! Sou Jefferson. Trabalho com: Dados, Dashboards, SQL, SAS, Python e muito mais! Criei esse cantinho para postar alguns conhecimentos. :)

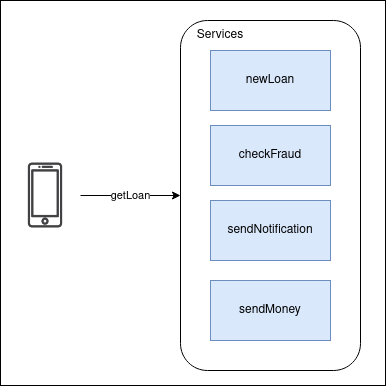
Salve, pessoal! Tudo certo? Você conhece o que é CDC (Change Data Capture)? Basicamente, CDC é uma técnica que, com base na leitura dos logs de um determinado banco transacional, realiza a leitura desses logs Leia mais