Mesmo depois de concluirmos uma arquitetura de dados ou construir uma aplicação, devemos nos preocupar com o monitoramento desse ambiente.
Perguntas como:
Qual o uso de CPU?
Quanto estou usando de memória?
Qual o trafego de rede?
Quanto ainda há de espaço disponível em disco?
São questões que perduram em nossa mente, e que são importantes para garantirmos um ambiente saudável.
Por esse motivo, trarei uma stack bem famosa quando falamos de monitoramento e ela será responsável por responder essas questões.
Para realizar o monitoramento, utilizaremos os três componentes abaixo:
Grafana
O Grafana irá cuidar da parte gráfica, provendo gráficos e alertas para cada métrica armazenada.
Telegraf
O Telegraf é o nosso coletor de métricas, basta instala-lo e inicia-lo que ele já coleta uma série de métricas como: CPU, memória, disco, rede, etc…
InfluxDB
O InfluxDB é nosso banco de dados para séries temporais e é ele quem armazenará as métricas coletadas pelo Telegraf.
Esses três softwares somados, formam uma poderosa stack de monitoramento. 😎
Sem mais delongas, vamos começar.
Pre-requisitos:
Não há muitos pre-requisitos para utilizar essa stack, como de costume, utilizarei o docker e docker-compose para subi-la, mas sinta-se livre para instalar em uma maquina comum.
Uma outra recomendação é utilizar Linux para cada artefato.
A propriedade user, pode ser utilizada para nomear cada maquina, no grafana, podemos agrupar as métricas coletadas por essa propriedade.
[agent]
As propriedades inclusas no agent, são configurações de como aquele agente irá coletar as métricas, tempo de batch, precisão das informações coletadas, se o telegraf irá rodar em modo de debug ou o nome do arquivo de log.
[inputs.*]
Essas são as métricas que queremos coletar, existem diversos inputs, para os mais diversos serviços, como Kafka, Zookeeper, Redis, Docker, etc… Você pode conferir uma lista completa no link abaixo:
Essas são as configurações para a conexão com o InfluxDB, além de definir o host onde fica o Influx, também definimos qual o nome do banco que iremos criar dentro do Influx, usuário e senha para acesso. Notem que para essas configurações, foram utilizadas variáveis de ambiente, pois tratam-se de informações sensíveis.
Para realizar a instalação, criei um dockerfile com o passo a passo. Seguirei esse modo de instalação pois ele será fácil de replicar.
FROM ubuntu:bionic
# Instalação
RUN apt-get update
RUN apt-get install -y wget
RUN wget https://dl.influxdata.com/telegraf/releases/telegraf-1.19.2_linux_amd64.tar.gz -P /opt
RUN tar xf /opt/telegraf-1.19.2_linux_amd64.tar.gz -C /opt
RUN mv /opt/telegraf-1.19.2 /opt/telegraf
# Entrypoint
ENTRYPOINT [ "/opt/telegraf/usr/bin/telegraf" ]
As configurações do InfluxDB, podem ser feitas através de um arquivo de configuração ou através de variáveis de ambiente, sendo que essas tem o prefixo “INFLUXDB_”.
No Linux, o arquivo de configuração deve ficar no seguinte diretório:
/etc/influxdb/influxdb.conf
Para esse teste, iremos utilizar o arquivo de configuração.
[meta]
dir = "/var/lib/influxdb/meta"
[data]
dir = "/var/lib/influxdb/data"
engine = "tsm1"
wal-dir = "/var/lib/influxdb/wal"
[meta]
O valor “dir”, define onde iremos armazenar os metadados.
[data]
O valor dir, define onde os dados serão armazenados
O valor engine, define como os índices serão armazenados, no caso, “tsm1”, define persistência de índices, o valor padrão “inmem” (em memória), define que o índice será recriado a cada reboot.
O valor wal-dir, define onde serão armazenados os logs.
Dockerfile de instalação:
FROM ubuntu:bionic
# Instalação
RUN apt-get update
RUN apt-get install -y wget
RUN wget https://dl.influxdata.com/influxdb/releases/influxdb-1.8.7_linux_amd64.tar.gz -P /opt
RUN tar xfz /opt/influxdb-1.8.7_linux_amd64.tar.gz -C /opt
RUN mv /opt/influxdb-1.8.7-1 /opt/influxdb
# Diretórios
RUN mkdir /etc/influxdb && mkdir /var/lib/influxdb
RUN mkdir /var/lib/influxdb/meta
RUN mkdir /var/lib/influxdb/data
RUN mkdir /var/lib/influxdb/wal
# Entrypoint
ENTRYPOINT [ "/opt/influxdb/usr/bin/influxd","run" ]
Para a instalação do Grafana, não há segredos. Basicamente, assim como nos artefatos anteriores, utilizei a versões binária para preparar o conteiner docker.
FROM ubuntu:bionic
# Instalação
RUN apt-get update
RUN apt-get install -y wget
RUN wget https://dl.grafana.com/oss/release/grafana-8.0.6.linux-amd64.tar.gz -P /opt
RUN tar xfz /opt/grafana-8.0.6.linux-amd64.tar.gz -C /opt
RUN mv /opt/grafana-8.0.6 /opt/grafana
# Diretórios
RUN mkdir /opt/grafana/data
RUN mkdir /opt/grafana/config
ENTRYPOINT [ "/opt/grafana/bin/grafana-server", "-homepath", "/opt/grafana"]
Iniciando a stack
Antes de iniciarmos os serviços, acredito ser necessário explicar algumas configurações do arquivo docker-compose.yml, pois essas configurações são importantes para a integração dos serviços.
Primeiramente, eu criei uma rede para a solução. Isso porque o IP do Influx deve permanecer o mesmo.
Outro ponto importante, é que a máquina que será monitorada é a que contém o Telegraf instalado. Instalaríamos esse agente na máquina que queremos monitorar. Eu poderia, por exemplo, ter um agente desses em cada nó de um cluster, ou em um serviço especifico, como um servidor web.
Os principais aspectos do arquivo de docker-compose é criar as variáveis de ambiente necessárias, e garantir a persistência dos dados através do ‘bind’ das pastas.
Se essa stack estivesse em uma máquina, ao invés de um contêiner, só precisaríamos nos preocupar com as variáveis de ambiente, já que uma máquina, diferente de um contêiner, não é efêmera com seus dados.
Bom, para iniciar a stack, devemos utilizar, dentro do projeto, os seguintes comandos:
docker-compose build
docker-compose up
O primeiro, cria os conteiners, executando nossa “receita de bolo” para cada artefato.
O segundo, inicia cada serviço, preocupando-se com a orquestração de cada um.
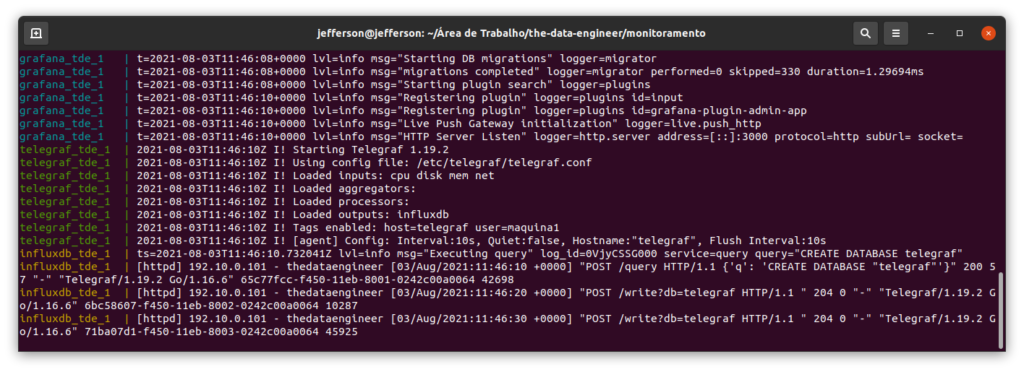
Após isso, teremos a stack executando no terminal:
Adicionando o InfluxDB no Grafana
Depois que nossa stack estiver rodando, podemos acessar o endereço do Grafana:
O programa pedirá uma nova senha, você pode escolher a que preferir
Depois disso, você será levado para a tela inicial do Grafana.
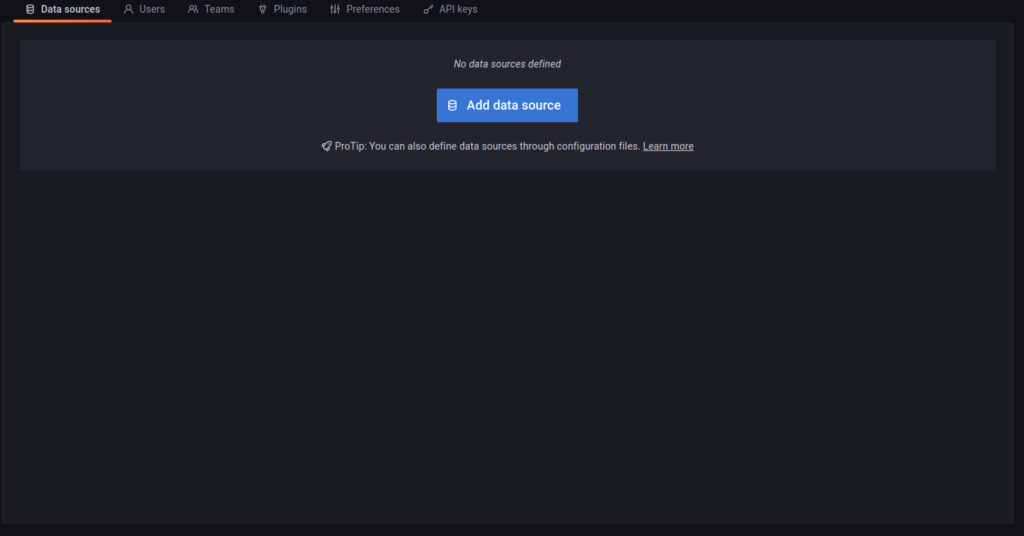
Agora, na barra lateral, temos um simbolo de engrenagem, iremos nele e depois em “Data sources”. Isso permitirá que adicionemos um novo data source, em nosso caso, o InfluxDB.
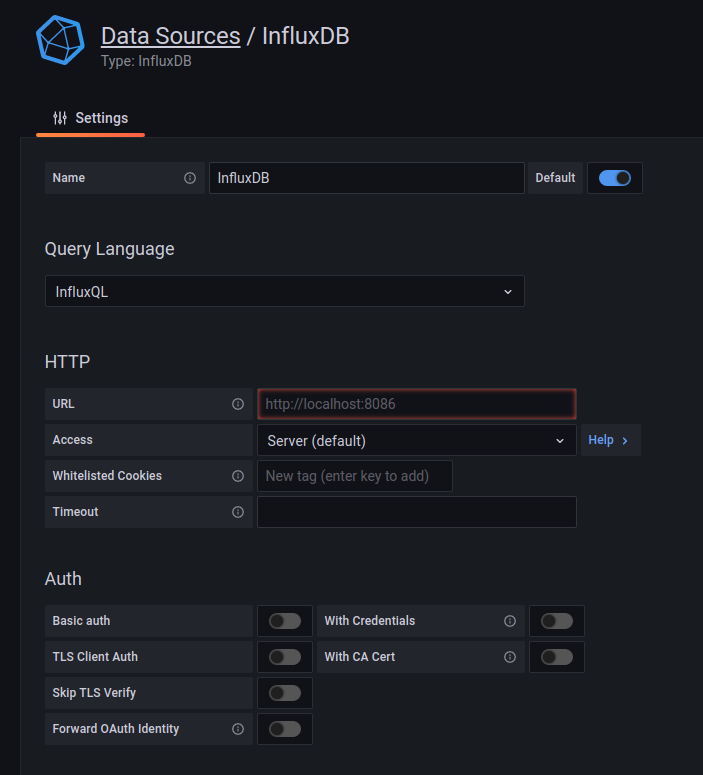
Quando selecionamos a opção InfluxDB, uma tela de configurações é habilitada:
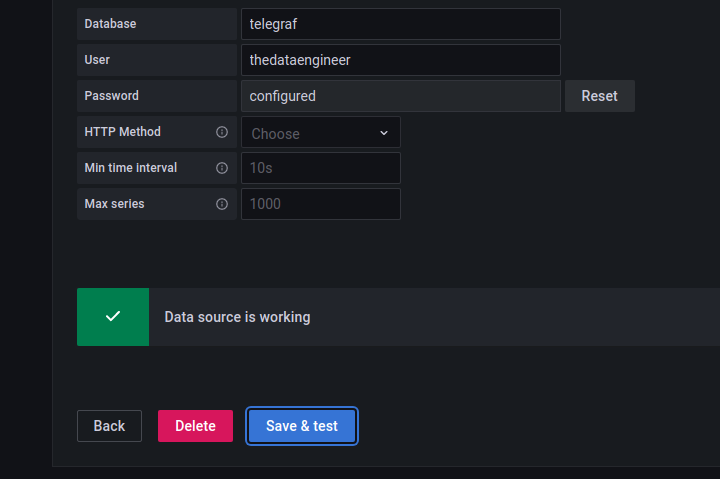
Todos esses dados já foram passados no setup do Telegraf, ou via variável de ambiente ou configuração.
Depois de realizar o preenchimento, basta clicar em “Save & test”.
A mensagem abaixo deverá ser exibida:
Criando o primeiro Gráfico
Agora que o trabalho pesado está pronto, vou mostrar um exemplo de como criar um gráfico dentro do Grafana, utilizando como fonte as métricas que armazenamos no InfluxDB.
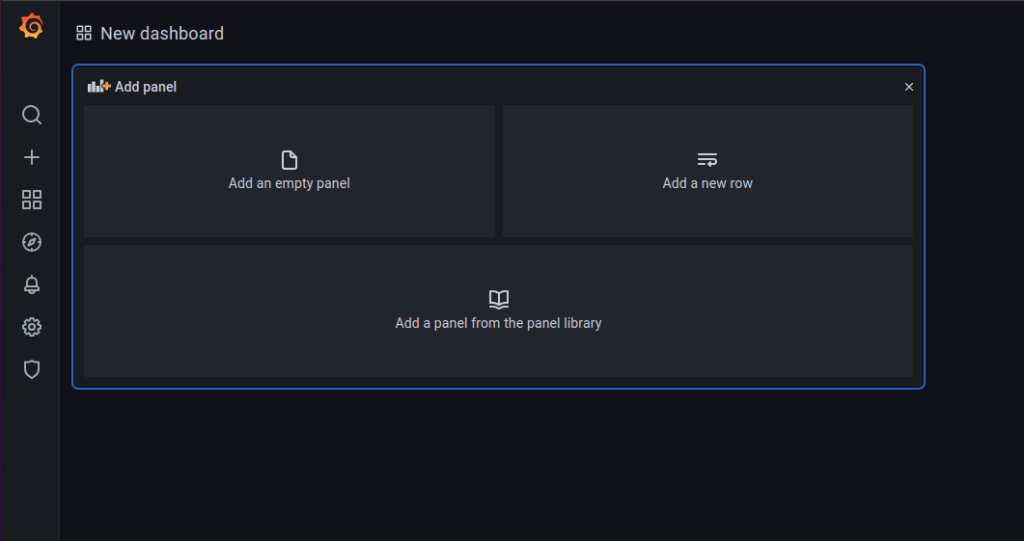
Primeiro, devemos criar um novo dashboard, no menu lateral, temos o simbolo de “+”, nele, podemos clicar em “Dashboard”.
Depois de clicar, a seguinte janela abrirá:
Nessa janela, poderemos adicionar nosso primeiro gráfico, em “Add an empty panel”. Após clicar na opção, você será direcionado para a ferramenta de edição, conforme a imagem abaixo:
Para exemplificar, vamos criar um gráfico para monitorar a memória disponível.
Primeiro, confirme se em “Data source” temos como opção nosso “InfluxDB”.
Feito isso, vá em “select measurement”, e selecione a opção “mem”.
Na opção “WHERE” poderíamos selecionar a máquina que queremos monitorar, lembra a opção de tag? Nas configurações do Telegraf? É ela que permite realizar essa opção. Mas como temos apenas uma máquina, não precisamos fazer essa parte.
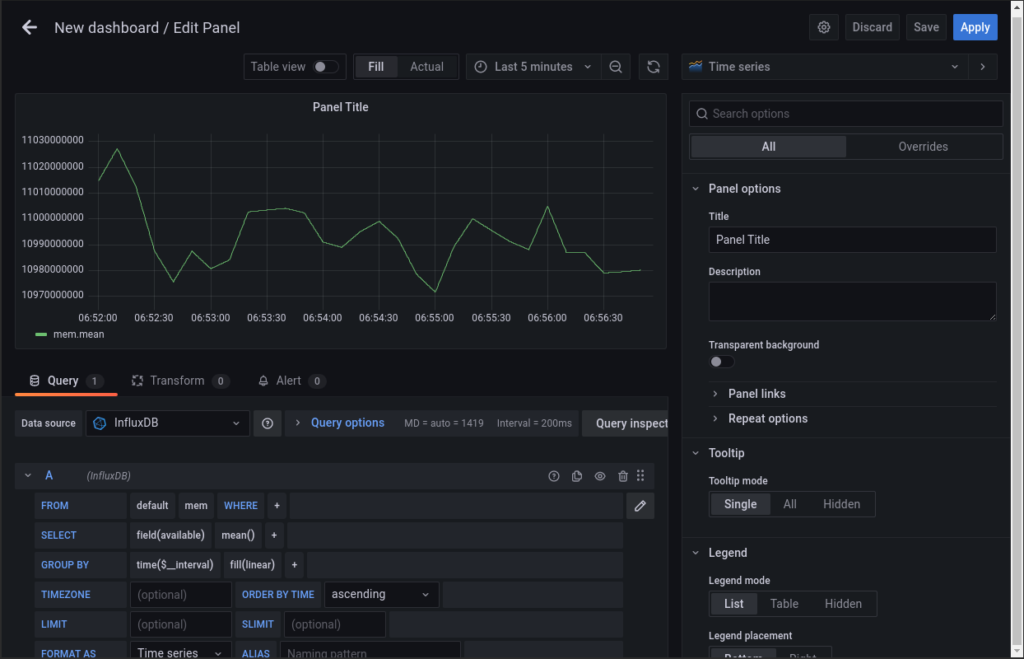
Feito isso, vamos em “field”, onde vamos selecionar qual a métrica de memória queremos, devemos então escolher “available”.
Em “GROUP BY” temos a opção “fill”, podemos deixar “linear”, isso deixará a linha sem quebras.
Uma ultima coisa que melhora a visualização é trocar o tempo de visualização para “Last 5 minutes”
Feito isso, já teremos o resultado abaixo:
Ainda podemos melhorar, no lado direito da ferramenta de edição, temos uma serie de opções como: titulo, descrição, tipo de gráfico, legenda dos eixos, qual a unidade de medida e etc…
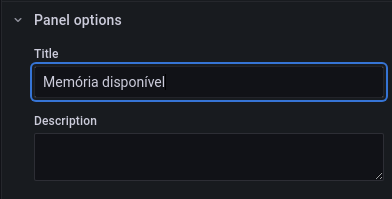
Vamos colocar titulo e unidade de medida, mas explore essas opções, elas são riquíssimas!
Titulo:
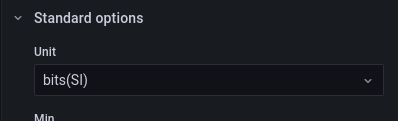
Unidade de medida (bits):
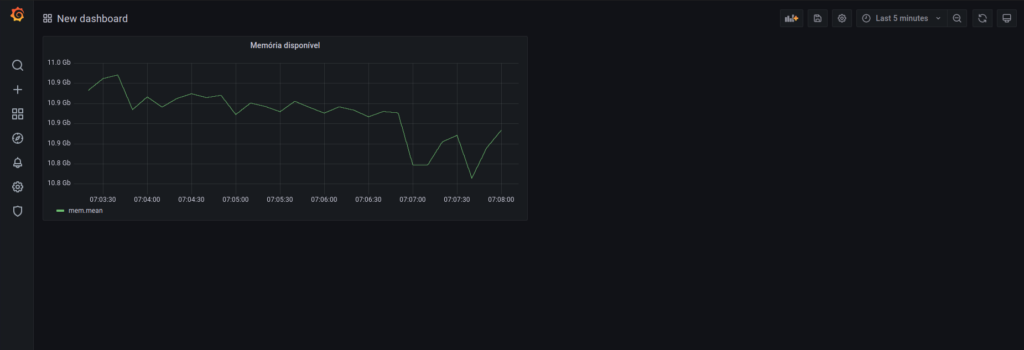
Feito isso, podemos salvar o gráfico, o resultado fica da seguinte forma:
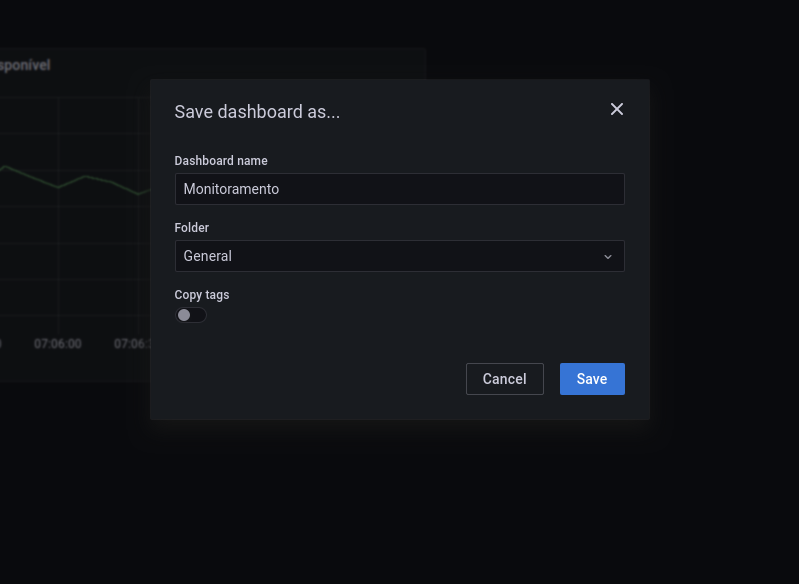
Após adicionar nosso gráfico, devemos salvar nosso dashboad, utilizando o botão de salvar, ao lado da opção “Last 5 minutes”.
Conclusão
Veja como foi fácil criar um gráfico no Grafana, podemos criar um para cada métrica e montar um painel geral com diversas informações e alertas.
Outra opção muito legal, é importarmos um painel da comunidade, com alguns passos, podemos importar um painel completo, com diversos gráficos já criados!
Espero que tenham gostado dessa postagem, e que ela lhe seja útil em seu dia a dia!
O monitoramento do ambiente é muito importante, e com poucas configurações, podemos montar um sistema de monitoramento completo, que consegue responder nossas perguntas inicias.
Ainda há diversos tópicos que eu poderia ter explorado, mas creio que o conteúdo abordado já é um norte para quem está começando.