Fala, pessoal! Tudo certo?
Quero trazer nessa postagem um pouco da ferramenta Elasticsearch, que em resumo, é um banco de dados de documentos.
Eu estudei a ferramenta nesses últimos dias e achei incrível a facilidade de instalação e uso.
Também achei muito legal o recurso de buscas de documentos que é incrivelmente rápido!
Além disso, a ferramenta funciona com uma Rest API, o que facilita muito a integração com outros sistemas.
Outro recurso legal é a utilização de plug-ins dentro do Elasticsearch, uma aplicação bem famosa que originou-se de um plug-in do Elasticsearch é o Kibana, que também veremos por aqui. 🙂
Nessa postagem irei abordar:
- Paralelo entre o modelo relacional e o Elasticsearch
- Instalação do Elasticsearch
- Instalação do Kibana
- Criando o primeiro index
- Criando o primeiro document
- Realizando a primeira pesquisa
Sem mais delongas, mãos à obra!
Fazendo um paralelo com os bancos relacionais
Abaixo temos uma tabela que tenta relacionar os conceitos do Elasticsearch com conceitos dos bancos relacionais.
| Relacional | Elasticsearch |
| Bancos | Index |
| Tabela | Type (Nas versões do Elasticsearch acima de 6 todos types são genéricos acessados através do comando _doc) |
| Esquema | Mapping |
| Tupla | Document |
| Coluna | Attribute |
Também temos as operações básicas de CRUD (create, retrieve, update e delete), mas elas funcionam com os verbos do mundo HTTP, visto que o Elasticsearch funciona com Rest API.
| Relacional | Elasticsearch |
| INSERT | POST |
| SELECT | GET |
| UPDADE | PUT (UPDADE OU INSERT SEM DUPLICAR) |
| DELETE | DELETE |
Apos fazermos esse paralelo com o mundo relacional, vamos à instalação. 🙂
Instalação do Elasticsearch
Primeiro devemos baixar o arquivo para nossa maquina, segundo o sistema operacional, no meu caso é o Linux.
Aqui você encontra o link para download: https://www.elastic.co/pt/downloads/elasticsearch
Uma vez baixado, devemos descompactar o conteúdo. No caso do meu sistema o comando é:
tar -xvf elasticsearch-7.12.1-linux-x86_64.tar.gzAo descompactar, termos dentro da pasta a seguinte estrutura de diretorios:
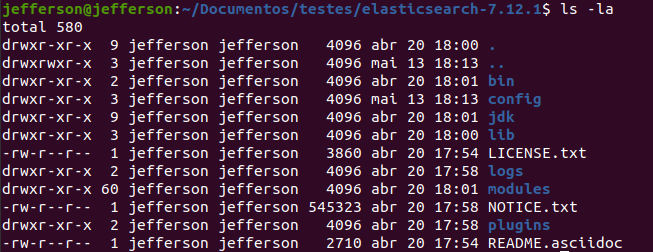
Dentro da pasta bin temos o executáveis para cada sistema.
Para linux e Mac OS X o arquivo é elasticsearch, no Windows o arquivo é elasticsearch.bat
Feito isso, está pronto!
OBS: Antes de iniciarmos o programa, devemos nos certificar que as portas 9200 e 9300 estejam livres, pois a aplicação utiliza essas portas.
Para executar o programa, devemos executar o binário:
./elasticsearchDepois de iniciar o elasticsearch, você pode acessar o endereço http://localhost:9200 e ver ele funcionando!
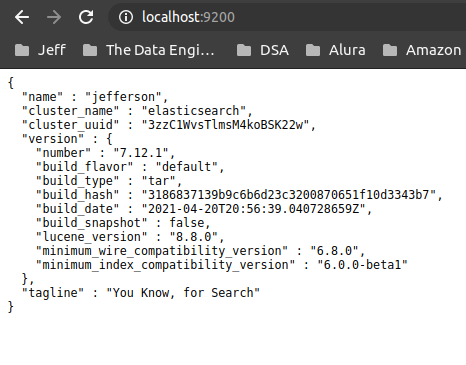
Com isso já temos o Elasticsearch funcionando!
Instalando o Kibana
Primeiro devemos baixar o arquivo segundo o sistema operacional:
Link de download: https://www.elastic.co/pt/downloads/kibana
Depois de baixar, devemos descompactar o arquivo.
tar -xvf kibana-7.12.1-linux-x86_64.tar.gzTemos praticamente os passos do Elasticsearch, executando o binário da pasta bin.
./kibanaOBS: Antes de executar o Kibana, tenha certeza que o Elasticsearch está funcionando e também que a porta 5601 esteja livre.
Depois disso poderemos acessar via navegador o endereço: http://localhost:5601
E pronto! O Kibana está instalado. 😀
Criando o primeiro índice
Para a criação do nosso primeiro índice, iremos utilizar o Kibana develop tool kit, dentro do proprio Kibana. Isso nos provê uma interface amigável para colocarmos os comandos HTTTP Rest.
No Kibana, então acesse Management > Dev Tools. O console abaixo deverá ser mostrado.
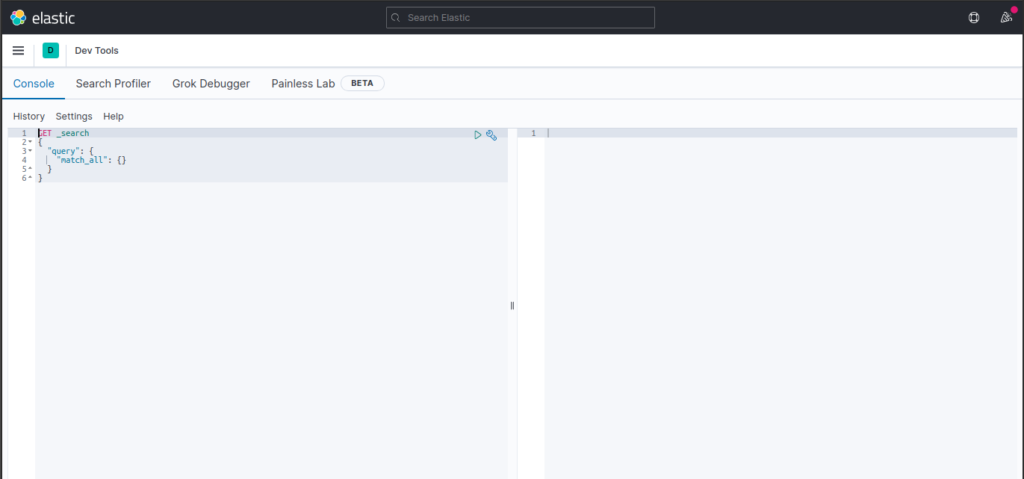
Para criarmos nosso primeiro índice, faremos o comando PUT com o nome do índice. E no corpo da requisição, colocaremos as configurações.
PUT /meu-primeiro-index
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 0
}
}
}
O nome do índice criado será meu-primeiro-index, como configuração teremos o numero padrão de shards (explicarei melhor em uma outra postagem o que são shards, mas você pode fazer um paralelo com as partições do mundo relacional), que são 3 e o numero de replicas como 0, isso por que estamos em um ambiente local e só temos uma maquina. Em um ambiente de cluster é boa pratica não deixar todos os dados em um só local.
Explicadas as configurações, podemos executar o comando no botão de “play” ao lado de onde está nosso comando PUT.
Quando fazermos isso, além do programa nos devolver o status 200 – OK, ele também nos devolve um corpo de resposta, informando que nosso índice foi criado e que ele entendeu que queríamos criar shards, colocando como true no corpo de resposta.

Um ponto importante aqui, por hora utilizarei o Kibana apenas para “conversar” com o Elasticsearch. Em um outro momento, trarei a parte de dashboads e analise com essa ferramenta.
Como são comandos HTTP Rest, eu poderia faze-los via wget ou curl, mas a interface do Kibana deixa tudo mais amigável.
Criando o primeiro Document
Para criamos o nosso primeiro documento, utilizaremos o comando POST lá dentro do Kibana. Extrai alguns dados do adorocinema para utilizar de exemplo. Abaixo os dados que iremos inserir:
POST meu-primeiro-index/_doc/
{
"titulo" : "O Poderoso Chefão",
"direcao" : "Francis Ford Coppola",
"roteiro" : ["Francis Ford Coppola","Mario Puzo"],
"elenco" : ["Marlon Brando", "Al Pacino", "James Caan"],
"nota" : 4.8,
"avaliacoes" : 6112,
"link_adorocinema" : "https://www.adorocinema.com/filmes/filme-1628/"
}E da mesma forma, obtemos um corpo de resposta:
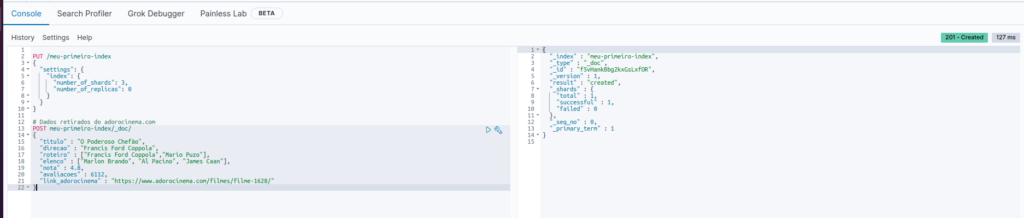
E nosso primeiro documento foi enviado com sucesso, podemos ver isso no atributo result do corpo de resposta:
{
"_index" : "meu-primeiro-index",
"_type" : "_doc",
"_id" : "f5vHankBbg2kxGsLxfOR",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}É interessante de observar é que o próprio Elasticsearch criou um ID para nosso documento (f5vHankBbg2kxGsLxfOR), se tentarmos inserir novamente ele irá criar um novo documento, veremos em outra postagem como resolver isso.
Outro ponto é que não criamos nenhuma estrutura para receber os dados, o Elasticsearch inferiu os tipos de dados e a estrutura.
Isso é bem legal, mas traz alguns problemas que veremos em um outro post, pois nesse vou me concentrar em apresentar a ferramenta.
Realizando a primeira pesquisa
Para realizar a primeira pesquisa, utilizaremos o método GET. Abaixo o comando correspondente:
GET meu-primeiro-index/_search
{
"query": {
"bool": {
"must": [
{"match": { "titulo": "O Poderoso Chefão"}}
]
}
}
}Quando fazemos a execução temos o resultado no corpo de resposta:
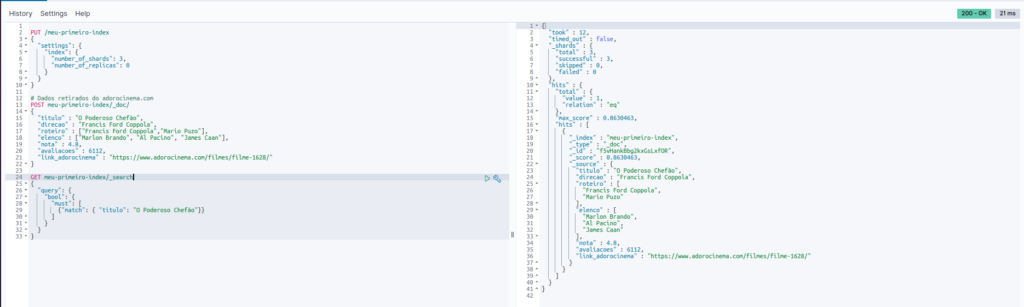
Dentro do atributo “hits” temos o atributo “value” com o valor de 1, que é a quantidade de resultados que a busca trouxe.
Um ponto legal de observar é que ele traz um score de relevância para aquela busca, no campo “max_score”, pois poderíamos ter outros filmes, como as sequencias, por exemplo.
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.8630463,
"hits" : [
{
"_index" : "meu-primeiro-index",
"_type" : "_doc",
"_id" : "f5vHankBbg2kxGsLxfOR",
"_score" : 0.8630463,
"_source" : {
"titulo" : "O Poderoso Chefão",
"direcao" : "Francis Ford Coppola",
"roteiro" : [
"Francis Ford Coppola",
"Mario Puzo"
],
"elenco" : [
"Marlon Brando",
"Al Pacino",
"James Caan"
],
"nota" : 4.8,
"avaliacoes" : 6112,
"link_adorocinema" : "https://www.adorocinema.com/filmes/filme-1628/"
}
}
]
}
}Conclusão
O Elasticsearch é uma ótima ferramenta! Muito fácil de instalar, configurar e utilizar.
Esse é um ótimo motor de buscas que você pode implementar em suas soluções, integrando facilmente ao seu sistema atual via API Rest.
Como essa é uma postagem básica, existem alguns pontos que precisam ser cobertos para que não haja erros na utilização. Como por exemplo:
- Criação do mapping (sem inferência do Elasticsearch)
- Analyzers (O que são e como interferem na busca)
- Id do index (Criando nosso próprio índice, e entendendo o controle de versão)
- bulk (inserindo dados de forma massiva)
Vou abordar esses aspectos na próxima postagem!
Até mais! 😀