Fala pessoal! Tudo certo? Conhecem o Apache NiFi?
Ele é uma das ferramentas da Apache que apoiam o big data stack, na parte de ingestão de dados!
A ferramenta é bem fácil de usar, pois tem uma interface web que é muito intuitiva.
Dentro dela, temos como se fossem “peças” (Processor), onde podemos montar nosso pipeline de dados, arrastando as peças que queremos para dentro do quadro.
Cada peça pode resolver um problema especifico, por exemplo:
- Recuperar dados de um diretório
- Disponibilizar dados em um servidor SSH
- Recuperar dados do HDFS
- Colocar dados em um servidor MySQL
- Converter dados para outro formato
- Enviar e-mail em caso de falha/sucesso
E por aí vai, pois a lista é bem longa!
O NiFi também permite que configuremos a recursão para algumas peças, normalmente utilizando uma string CRON.
Nesse exemplo, irei consumir os dados da API do CartolaFC, utilizando o Apache NiFi.
Creio que servirá de exemplo para consumir outras API’s.
Bora lá! 😀
Iniciando…
Por hora, não irei mostrar a instalação do NiFi, trago isso em um outro momento. O importante é entender que tenho um ambiente de teste que tem um cluster Hadoop e o NiFi instalado.
Com o NiFi iniciado, crie um novo Process Group:
Depois, devemos entrar no Process Group criado, clicando duas vezes sobre o objeto.
Isso abrirá uma tela limpa, onde podemos iniciar nosso pipeline. E também ajuda na organização dos fluxos.
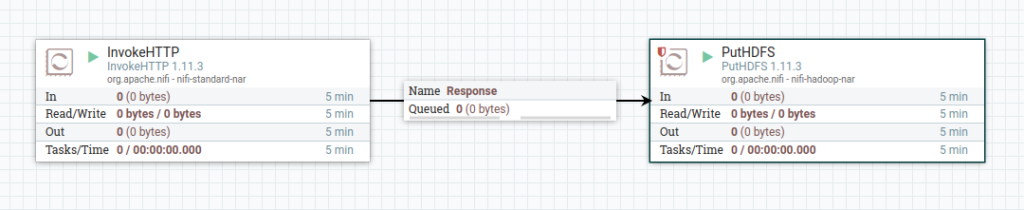
Para esse pipeline, utilizaremos dois Processors.
InvokeHTTP e PutHDFS
Primeiro trazemos um processor para dentro da tela, pesquisamos o InvokeHTTP e adicionamos.
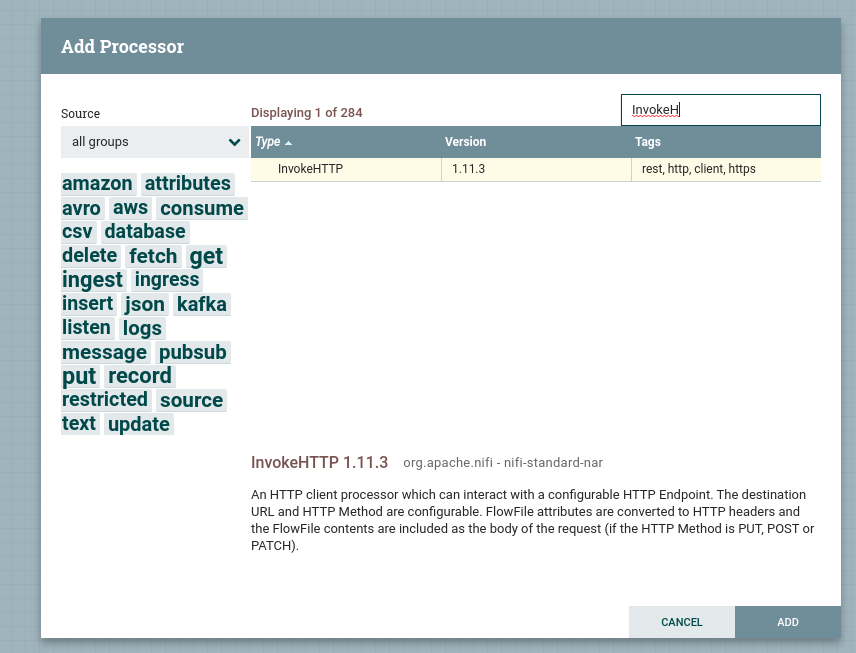
Repetimos o mesmo passo para adicionar o PutHDFS.
No final, teremos os dois processors adicionados, mas sem nenhuma configuração.
Configurando os Processors
Para entrar nas configurações, podemos clicar no objeto com o botão direito do mouse e ir em “Configure”.
Dentro das configurações desse objeto temos 4 abas.
- Settings
- Scheduling
- Properties
- Comments
Isso é igual para os dois Processors que estamos vendo aqui.
InvokeHTTP
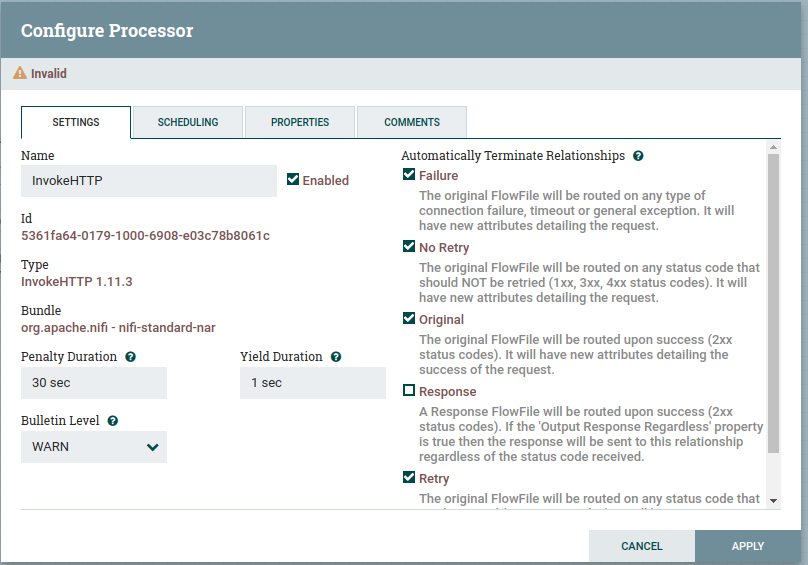
Na aba de settings, preencheremos conforme a configuração abaixo, basicamente configurando a resposta da API como unica saída valida.
Essa saída irá gerar um FlowFile e é ele que será passado para o PutHDFS quando criarmos a relação.
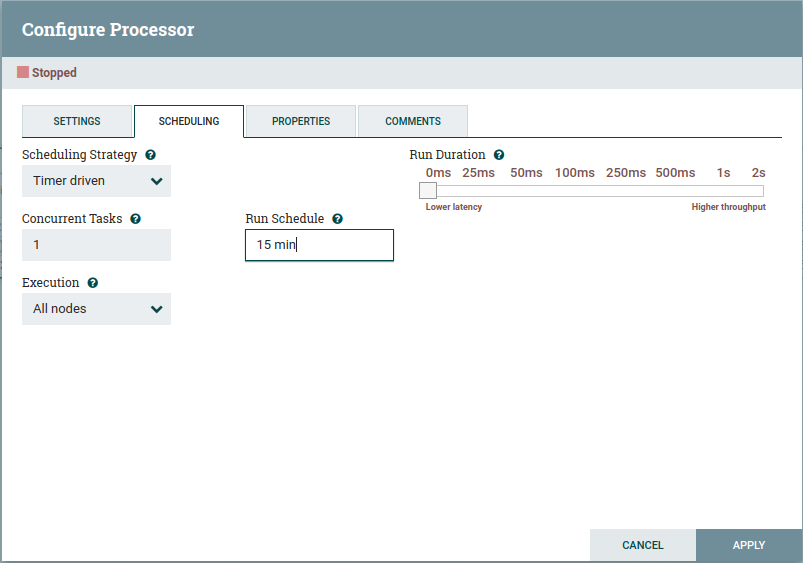
Na aba de schedule, iremos colocar a recursão, no meu caso, coloquei de 15 min em 15 minutos.
Nas properties, colocamos o endpoint da API, basicamente.
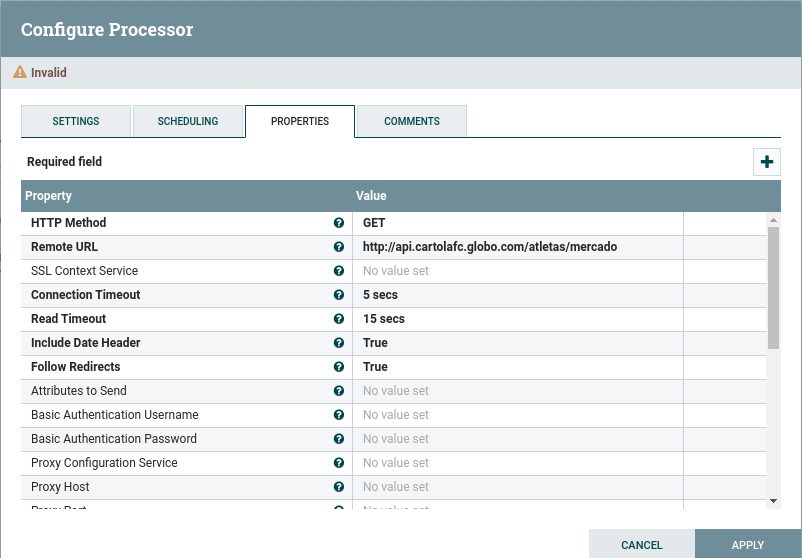
Feito isso, basta darmos um “APPLY”.
PutHDFS
Na aba settings, preencheremos conforme abaixo, basicamente setando failure e success.
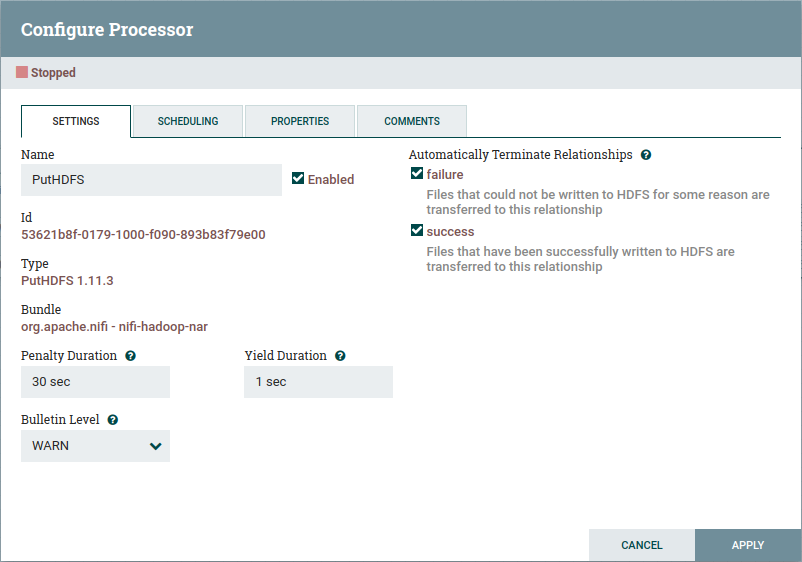
Pularemos a aba scheduling e iremos direto à properties.
Nela, precisamos colocar onde estão os arquivos de configuração do HDFS (core-site.xml e hdfs-site.xml) na maquina, pois, é com base neles que a conexão com o HDFS acontece.
O caminho dos arquivos devem ser passados no campo Hadoop Configuration Resources, separador por virgula.
No campo Directory devemos passar o caminho onde serão armazenados os dados.
E no campo Conflict Resolution Strategy, a estrategia adotada quando temos dois arquivos com o mesmo nome, no meu caso coloquei replace.
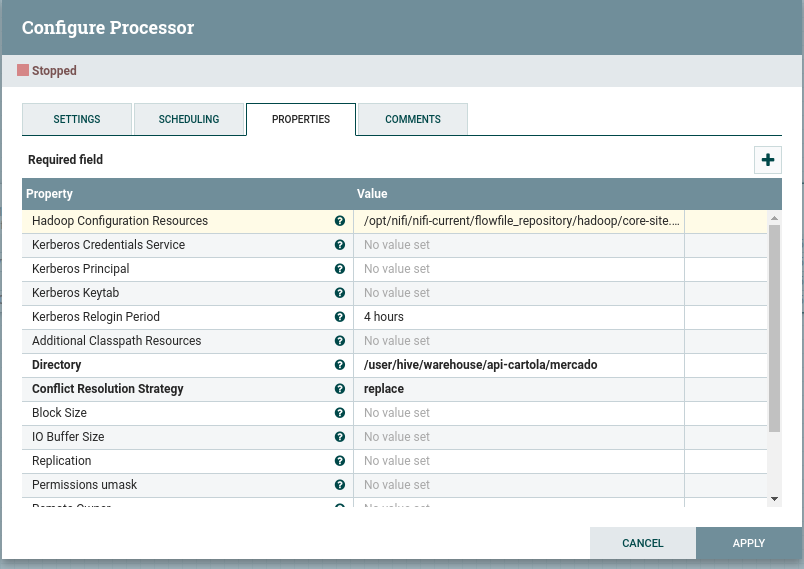
Feito isso, podemos dar um “APPLY”.
Terminamos a configuração
Ligando os Processors
Agora precisamos ligar os processors, para isso devemos ir no objeto InvokeHTTP e colocar o mouse por cima dele. Ele exibirá uma “flecha” e é ela que usamos pra fazer a ligação, arrastando-a para o objeto PutHDFS.
Isso fará com que as configurações de conexão sejam exibidas, no caso, deixaremos apenas “Response” como valida.
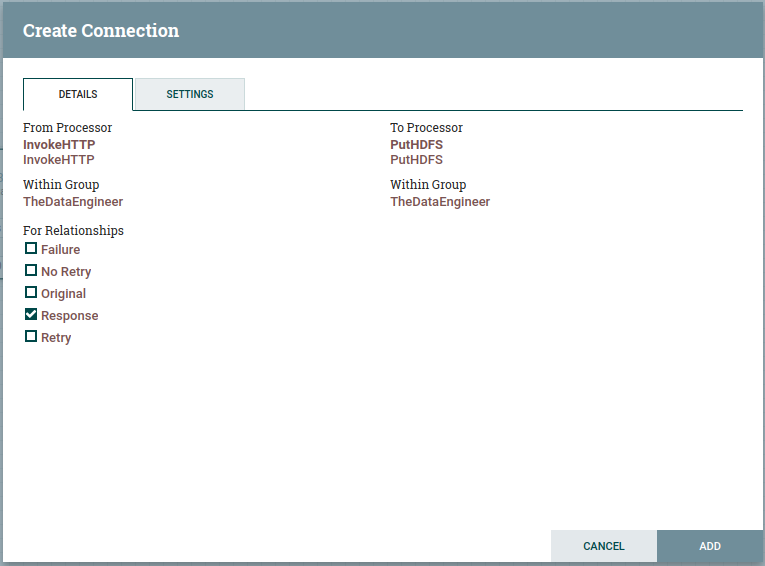
Feito isso, podemos dar um “ADD”.
E teremos nosso pipeline configurado no NiFi. 🙂
Startando o Pipeline
Para iniciar o pipeline basta irmos na parte de navegação do nosso Process Group e dar um “start” .
Depois do tempo de recursão poderemos conferir os dados no HDFS 🙂
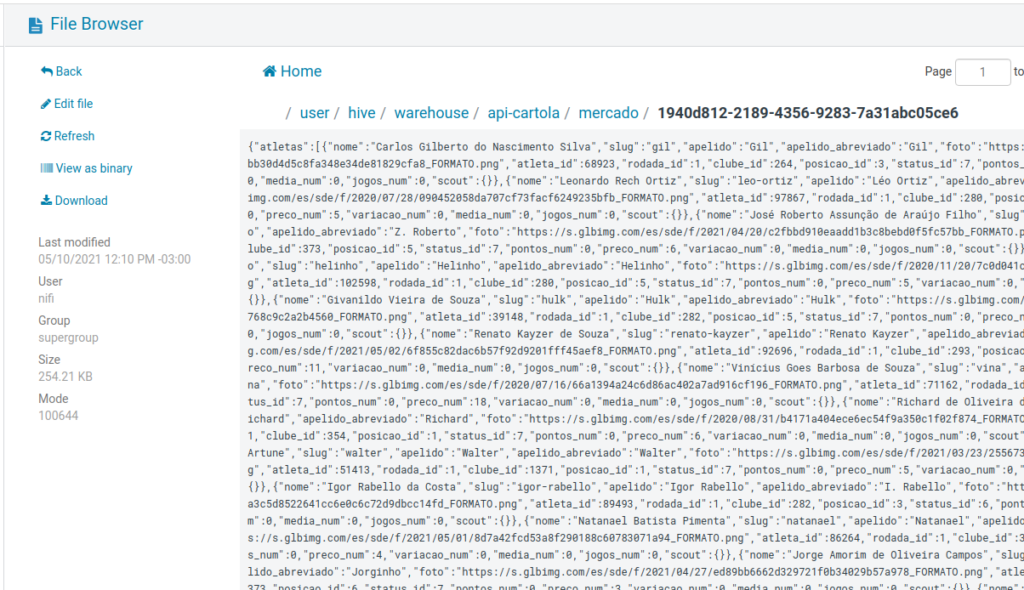
Pronto! A ingestão está feita!
Conclusão
Esse foi um exemplo simples de como consumir os dados de uma API Rest, o NiFi nos dá muitas outras coisas que poderíamos ter feito, como tratamentos, alertas e variáveis dentro dos Processors.
Eu quis manter o mais simples possível, e abordarei alguns desses pontos em um outro momento por aqui!
Mas por hoje é isso! Espero que seja útil e que tenham gostado!
Um abraço e até mais!

